Omówienie raportu P1 — Od krzywych rotacji do słabego soczewkowania: jak sprawdzić średnią odpowiedź grawitacyjną EFT
Popularnonaukowy przewodnik oparty na raporcie P1_RC_GGL: ścisły test domknięcia dynamiki galaktyk i słabego soczewkowania (v1.1)
Zapoznaj się z oryginalnym raportem z ewaluacji:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
Uwaga do lektury |
To jest wersja objaśniająca, a nie osobny raport akademicki. Opiera się na oryginalnym raporcie P1, zachowuje kluczowe ryciny i tabele oraz dodaje przystępne wyjaśnienia tego, co oznacza każdy ważny etap. |
Tekst objaśnia wyłącznie wnioski P1 w ramach wskazanych tam zbiorów danych, rejestru parametrów i protokołu statystycznego: w łącznym teście krzywych rotacji galaktyk (RC) i słabego soczewkowania galaktyka–galaktyka (GGL) model średniej odpowiedzi grawitacyjnej EFT wyraźnie przewyższa minimalną bazę DM_RAZOR testowaną w tym raporcie. |
Ten przewodnik nie interpretuje P1 jako twierdzenia, że „ciemna materia została obalona”. P1 jest tylko pierwszym krokiem w eksperymentach serii P. Testuje jedną obserwowalną warstwę EFT — „średnie podłoże grawitacyjne” — a nie pełną treść całego frameworku EFT. |
0 | P1 w pięć minut: co właściwie robi ten test?
P1 można rozumieć jako test spójności między sondami obserwacyjnymi. Nie pyta on po prostu, czy model potrafi dopasować jeden zbiór danych. Zamiast tego stawia na tym samym stole audytowym dwa bardzo różne odczyty grawitacji: krzywe rotacji (RC) odczytują dynamikę wewnątrz dysków galaktyk, a słabe soczewkowanie galaktyka–galaktyka (GGL) odczytuje rzutowaną odpowiedź grawitacyjną w większych skalach.
- RC działa jak prędkościomierz: mówi, jak szybko gaz i gwiazdy krążą na różnych promieniach w dysku galaktyki.
- GGL działa jak waga: mierząc, jak galaktyki pierwszego planu lekko zakrzywiają światło galaktyk tła, pozwala wnioskować o średnim rozkładzie grawitacji/masy wokół galaktyk w większych skalach.
- Główne pytanie P1 brzmi: czy ten sam model potrafi najpierw nauczyć się wzorca z RC, a następnie przenieść ten wzorzec na GGL i nadal zachować sensowność?
P1 w jednym zdaniu |
P1 podnosi poprzeczkę z pytania „czy model dobrze pasuje do jednej sondy?” do pytania „czy domyka się między sondami?”. Model z większym prawdopodobieństwem uchwycił strukturę grawitacyjną wspólną dla RC i GGL tylko wtedy, gdy dobrze działa przy poprawnym odwzorowaniu, a sygnał zapada się po przetasowaniu odwzorowania. |
Tabela 0 | Kluczowe liczby P1 i ich proste odczytanie
Metryka | Odczyt w P1 / P1A | Znaczenie w języku potocznym |
Łączne dopasowanie ΔlogL_total | W głównym porównaniu z tekstu głównego EFT jest o 1155–1337 powyżej DM_RAZOR | Różnica łącznego wyniku dla dwóch zbiorów danych; im większa, tym lepsze ogólne wyjaśnienie. |
Siła domknięcia ΔlogL_closure | W głównym porównaniu EFT ma 172–281, a DM_RAZOR 127 | Zdolność przewidywania GGL po wnioskowaniu wyłącznie z RC; im większa, tym silniejsza samospójność między sondami. |
Kontrola negatywna shuffle | Po przetasowaniu RC-bin→GGL-bin sygnał domknięcia EFT spada do 6–23 | Jeżeli poprawna odpowiedniość zostaje złamana, przewaga powinna zniknąć; im ostrzejsze załamanie, tym mocniej wyklucza to sygnał pozorny. |
Wielomodelowy test stresowy DM w P1A | DM 7+1 + DM_STD, z zachowanym EFT_BIN jako porównaniem | P1A nie patrzy tylko na minimalną bazę DM_RAZOR. Umieszcza kilka niskowymiarowych, audytowalnych gałęzi wzmocnienia DM w tym samym protokole domknięcia. |
1 | Po co robić P1? Gdzie blokuje się kosmologia w skali galaktyk?
Problemy w skali galaktyk pozostają trudne, ponieważ „wymóg dodatkowej grawitacji/masy” nie jest wyłącznie zjawiskiem krzywych rotacji. Wiele obserwacji pokazuje ścisły związek między widzialną materią barionową w galaktykach a rzeczywistymi odczytami dynamicznymi i soczewkowymi. Dla ścieżki ciemnej materii oznacza to, że ciemne halo, sprzężenie zwrotne barionów, historia formowania galaktyk i systematyki obserwacyjne muszą być skoordynowane z bardzo dużą precyzją. Dla ścieżek grawitacji bez ciemnej materii oznacza to, że model nie może dobrze wyglądać tylko na RC; musi też przetrwać słabe soczewkowanie, relacje skalowania populacji i kontrole negatywne.
To właśnie motywuje P1. Raport nie wychodzi od hasła „ciemna materia jest błędna” ani od założenia „EFT musi mieć rację”. Bierze do audytu jedną testowalną tezę: czy średnia odpowiedź grawitacyjna EFT może pozostawić odtwarzalny i przenoszalny sygnał w domknięciu RC→GGL między sondami?
Zewnętrzny kontekst literatury: dlaczego okno RC+GGL jest ważne |
Radial acceleration relation (RAR), zaproponowana przez McGaugha, Lellego i Schomberta w 2016 roku, pokazuje ścisłą korelację o małym rozrzucie między obserwowanym przyspieszeniem śledzonym przez krzywe rotacji a przyspieszeniem przewidywanym z materii barionowej. Sprawia to, że „sprzężenie bariony–odpowiedź grawitacyjna” staje się nie do ominięcia w teorii skali galaktyk. |
Brouwer i in. (2021) wykorzystali słabe soczewkowanie KiDS-1000, aby rozszerzyć RAR na niższe przyspieszenia i większe promienie, porównując modele MOND, emergent gravity Verlindego i LambdaCDM. Wskazali też, że różnice między galaktykami wczesnego i późnego typu, halo gazowe oraz relacja galaktyka–halo pozostają kluczowymi problemami wyjaśniającymi. |
Mistele i in. (2024) użyli następnie słabego soczewkowania do wyprowadzenia krzywych prędkości kołowych dla izolowanych galaktyk, raportując brak wyraźnego spadku aż do kilkuset kpc, a nawet około 1 Mpc, zgodnie z BTFR. Pokazuje to, że słabe soczewkowanie staje się ważnym zewnętrznym odczytem do testowania odpowiedzi grawitacyjnej w skali galaktyk. |
Wartość P1 nie polega więc na tym, że jest „pierwszą pracą omawiającą RC i GGL razem”. Polega na tym, że umieszcza je w audytowalnym protokole złożonym ze stałego odwzorowania, rejestru parametrów, domknięcia RC-only→GGL, kontroli negatywnej przez tasowanie oraz wielomodelowych testów stresowych DM w P1A.
2 | Co oznacza EFT w P1? To nie jest Effective Field Theory
Tutaj EFT oznacza Teorię Włókna Energii (Energy Filament Theory, EFT), a nie Effective Field Theory powszechnie używaną w fizyce. W raporcie technicznym P1 EFT jest używana oszczędnie: nie występuje w porównaniu jako kompletna teoria końcowa, lecz zostaje najpierw skompresowana do obserwowalnej, gotowej do dopasowania i falsyfikowalnej parametryzacji „średniej odpowiedzi grawitacyjnej”.
W prostych słowach: P1 nie zaczyna od omawiania wszystkich mikroskopowych źródeł dodatkowej grawitacji i nie próbuje od razu udowodnić całego frameworku EFT. Stawia węższe i twardsze pytanie: jeżeli w skalach galaktycznych istnieje pewna średnia dodatkowa odpowiedź grawitacyjna, to czy może najpierw wyjaśnić RC, a potem przenieść się na przewidywanie GGL?
Którą część EFT testuje P1? |
P1 celuje w „średnie podłoże grawitacyjne” (mean gravity floor): statystycznie stabilny średni wkład, który może przenosić się między próbkami. |
P1 nie obsługuje jeszcze „podłoża stochastycznego/szumowego” (stochastic/noise floor): losowych składników, różnic indywidualnych lub dodatkowego rozrzutu, które mogą wprowadzać bardziej mikroskopowe procesy fluktuacyjne. |
P1 nie zajmuje się również pełnym mechanizmem mikroskopowym, obfitością, czasem życia ani globalnymi ograniczeniami kosmologicznymi. To pierwszy krok w eksperymentach serii P, nie ostateczny werdykt. |
3 | Plan serii P1: dlaczego zacząć od „średniego podłoża”?
Serię P można rozumieć jako program obserwacyjnego odzyskiwania EFT. Nie wykłada ona wszystkich tez naraz; zamiast tego izoluje tę część, którą najłatwiej przetestować na publicznych danych. Strategia P1 polega na przetestowaniu najpierw składnika średniego: jeżeli średnia odpowiedź grawitacyjna nie potrafi nawet domknąć się z RC do GGL, to dyskusja o bardziej złożonych składnikach szumowych lub mechanizmach mikroskopowych nie ma właściwego punktu wejścia.
Tabela 1 | Warstwowe pozycjonowanie serii P
Warstwa | Zadawane pytanie | Rola w P1 |
P1 | Czy średnia odpowiedź grawitacyjna może domknąć się w RC→GGL? | Główne pytanie obecnego raportu |
P1A | Jeżeli strona DM zostanie wzmocniona, czy wniosek pozostaje stabilny? | Aneks B: test stresowy DM 7+1 + DM_STD |
Późniejsze prace serii P | Czy protokół można rozszerzyć na więcej danych, więcej sond i bardziej złożone systematyki? | Kierunek przyszłych prac |
Pytania głębszego poziomu | Jak łączą się składnik średni, składnik szumowy i mechanizm mikroskopowy? | Poza zakresem wniosków P1 |
4 | Czym są dane? Co mówią nam RC i GGL?
4.1 Krzywe rotacji (RC): „miernik prędkości” wewnątrz dysków galaktyk
Krzywe rotacji zapisują, jak szybko gaz i gwiazdy krążą wokół centrum galaktyki na różnych promieniach. Im szybsza rotacja, tym silniejsza siła dośrodkowa jest wymagana na danym promieniu — a więc tym silniejsza jest efektywna grawitacja. P1 wykorzystuje bazę SPARC; po wstępnym przetworzeniu obejmuje ona 104 galaktyki i 2295 punktów prędkości, podzielone na 20 binów RC.
4.2 Słabe soczewkowanie (GGL): „waga grawitacyjna” w większej skali
Słabe soczewkowanie galaktyka–galaktyka mierzy, jak galaktyki pierwszego planu lekko zakrzywiają światło galaktyk tła. Odpowiada ono rzutowanej odpowiedzi grawitacyjnej na większych promieniach, w skali halo, i nie zależy od szczegółów dynamiki gazu wewnątrz galaktyki. P1 wykorzystuje publiczne dane GGL z KiDS-1000 / Brouwer i in. (2021): 4 biny masy gwiazdowej, po 15 punktów radialnych w każdym binie, łącznie 60 punktów danych, z użyciem pełnej kowariancji.
4.3 Stałe odwzorowanie: dlaczego 20 binów RC → 4 biny GGL ma znaczenie?
P1 łączy 20 binów RC z 4 binami GGL według stałej reguły: każdy bin GGL odpowiada 5 binom RC, połączonym średnią ważoną liczbą galaktyk. To odwzorowanie pozostaje niezmienione dla wszystkich modeli i działa jako twarde ograniczenie w teście domknięcia oraz uczciwym porównaniu.
Dlaczego nie dostrajać odwzorowania po fakcie? |
Gdyby można było po fakcie wybierać, „które biny RC odpowiadają którym binom GGL”, model mógłby wytwarzać domknięcie przez przestawianie odpowiedniości. P1 z góry blokuje odwzorowanie 20→4 i celowo niszczy je kontrolą negatywną shuffle właśnie po to, by ocenić, czy sygnał domknięcia naprawdę zależy od fizycznie rozsądnej odpowiedniości. |
5 | Modele i metody: co dokładnie porównuje P1?
5.1 Strona EFT: niskowymiarowa średnia odpowiedź grawitacyjna
Po stronie EFT do opisu średniej odpowiedzi grawitacyjnej używa się niskowymiarowego dodatkowego składnika prędkości. Kształt tego składnika kontroluje bezwymiarowa funkcja jądra f(r/ℓ), gdzie ℓ jest skalą globalną, a amplituda jest przypisana według binu RC. Różne jądra reprezentują różne początkowe nachylenia, szybkości przejścia i ogony dalekiego zasięgu, dlatego służą do testów stresowych odporności.
5.2 Strona DM: główne porównanie w tekście i Aneks P1A trzeba czytać osobno
W głównym porównaniu tekstu DM_RAZOR jest zminimalizowaną, audytowalną bazą NFW: używa stałej relacji c–M i nie obejmuje rozrzutu halo-do-halo, kontrakcji adiabatycznej, rdzeni sprzężenia zwrotnego, niesferyczności ani składników środowiskowych. Siłą tego projektu są kontrolowane stopnie swobody i łatwa odtwarzalność; słabością jest to, że nie może reprezentować każdego modelu LambdaCDM ani każdego modelu halo ciemnej materii.
Dlatego w Aneksie B (P1A) strona DM zostaje przekształcona w zestaw „standaryzowanych testów stresowych”. Bez zmiany wspólnego odwzorowania ani protokołu domknięcia P1A stopniowo dodaje niskowymiarowe gałęzie wzmocnienia, takie jak SCAT, AC, FB, HIER_CMSCAT, CORE1P, lensing m oraz połączona baza DM_STD, zachowując EFT_BIN jako porównanie. Krótko mówiąc, P1A nie porównuje tylko z jedną minimalną bazą DM; mierzy zestaw typowych, audytowalnych mechanizmów DM tą samą „miarą domknięcia”.
Precyzyjna rama wnioskowania używana tutaj |
Tekst główny: rodzina EFT znacząco przewyższa minimalny DM_RAZOR w głównym porównaniu. |
Aneks B / P1A: przy wielu niskowymiarowych, audytowalnych gałęziach wzmocnienia DM oraz teście stresowym DM_STD niektóre wspólne dopasowania DM poprawiają się, ale siła domknięcia nie usuwa przewagi EFT_BIN. |
Najbezpieczniejsze sformułowanie brzmi więc: w ramach danych, odwzorowania, rejestru parametrów i protokołu domknięcia P1/P1A średnia odpowiedź grawitacyjna EFT wykazuje silniejszą spójność między zbiorami danych; nie jest to równoznaczne z wykluczeniem wszystkich modeli ciemnej materii. |
5.3 Test domknięcia: najważniejsza składnia eksperymentalna P1
1. Dopasować model wyłącznie do RC, aby otrzymać zestaw próbek posteriori RC-only.
2. Nie dostrajać ponownie przy użyciu GGL; użyć posteriori RC bezpośrednio do przewidywania GGL.
3. Użyć pełnej kowariancji do obliczenia wyniku przewidywania GGL przy poprawnym odwzorowaniu, logL_true.
4. Losowo spermutować odpowiedniość RC-bin→GGL-bin, aby obliczyć wynik kontroli negatywnej, logL_perm.
5. Odjąć te dwie wielkości, aby uzyskać siłę domknięcia: ΔlogL_closure = <logL_true> − <logL_perm>.
Analogia w prostym języku |
Test domknięcia jest jak egzamin poprawkowy w innej sali. Model najpierw uczy się wzorców w sali RC, a potem odpowiada w sali GGL. Jeżeli nauczył się wspólnej reguły, a nie lokalnej sztuczki, powinien nadal odpowiadać dobrze po zmianie sali; jeżeli odpowiedniość między salami egzaminacyjnymi zostanie celowo przetasowana, przewaga powinna zniknąć. |
5.4 Zanim przeczytasz tabele techniczne: cztery punkty wejścia
Tabela 5.4 | Ścieżka czytania kolejnego zestawu poziomych tabel technicznych
Punkt wejścia | Na co patrzeć | Dlaczego to ważne |
Tabela S1a | Łączny wynik dopasowania RC+GGL | Odpowiada na pytanie: „Gdy oba zbiory danych ogląda się razem, czyje ogólne wyjaśnienie jest silniejsze?” |
Tabela S1b | Siła domknięcia, shuffle i skany odporności | Odpowiada na pytanie: „Czy to, czego nauczono się z RC, przenosi się na GGL?” |
Tabela B0 | Definicje wielu gałęzi wzmocnienia DM w P1A | Zapobiega redukowaniu P1 do „porównania tylko z minimalnym DM_RAZOR”. |
Tabela B1 | Tabela wyników domknięcia i łącznego dopasowania w P1A | Sprawdza, czy przewaga domknięcia znika po wzmocnieniu DM. |
Uwaga układu strony |
Strony poziome zaczynają się na następnej stronie, aby szerokie tabele z oryginalnego raportu mogły pozostać nienaruszone, bez usuwania kolumn i bez kompresowania ich do nieczytelności. Tekst główny podał już odczyt w języku potocznym; poziome tabele techniczne są przeznaczone dla czytelników, którzy muszą sprawdzić wartości i gałęzie modeli. |
Rycina 0.1 | Przepływ pracy testu domknięcia P1 na jednym diagramie
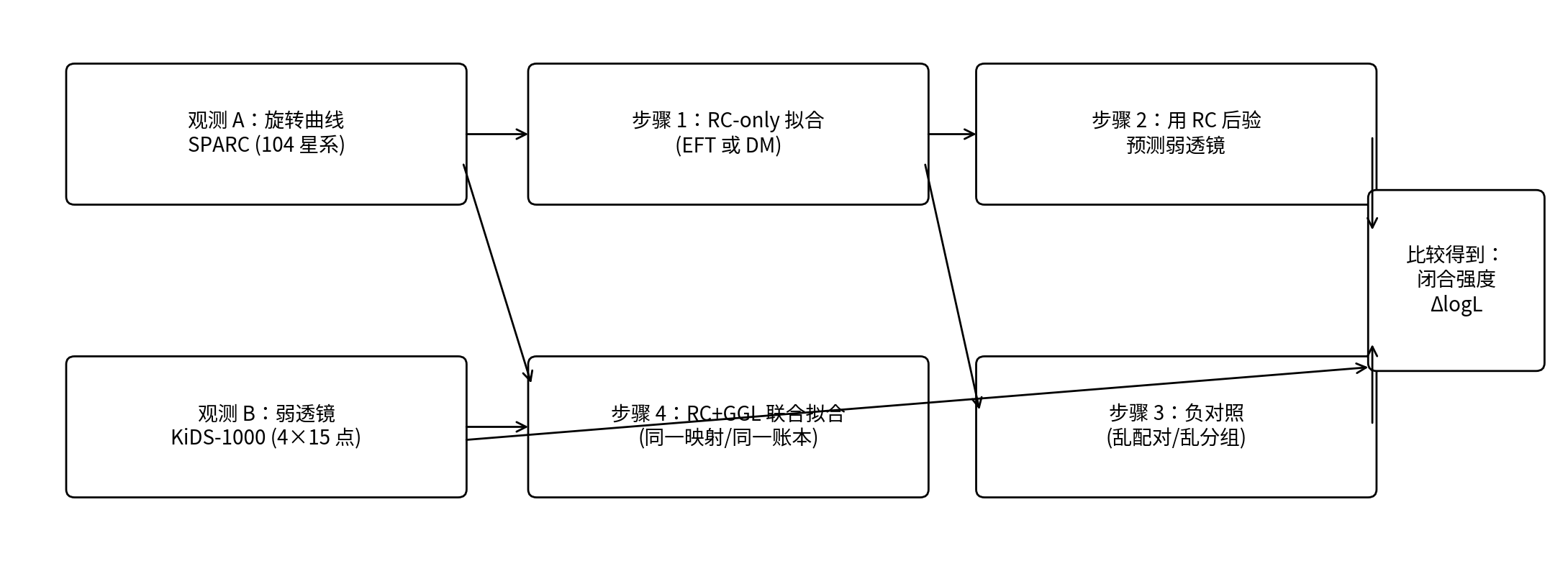
Uwaga: górny łańcuch to „test domknięcia” (dopasuj tylko RC → użyj posteriori RC do przewidywania GGL); dolny łańcuch to „dopasowanie łączne” (punktuj RC+GGL razem). Po prawej porównuje się prawdziwe odwzorowanie z odwzorowaniem przetasowanym, aby uzyskać siłę domknięcia ΔlogL.
6 | Kluczowe tabele techniczne: główne tabele z oryginalnego raportu i tabele P1A
Tabela S1a | Główne metryki porównania dopasowania łącznego (RC+GGL, Strict; zachowane z oryginalnego raportu)
Model (workspace) | Jądro W | k | Łączne logL_total (best) | ΔlogL_total względem DM | AICc | BIC |
DM_RAZOR | brak | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | brak | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabela S1b | Metryki domknięcia i odporności (Strict; zachowane z oryginalnego raportu)
Model (workspace) | Domknięcie ΔlogL (true-perm) | ΔlogL po kontroli negatywnej shuffle | Zakres ΔlogL w skanie σ_int | Zakres ΔlogL w skanie R_min | Zakres ΔlogL w skanie cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
Tabela B0 | Definicje gałęzi wzmocnienia DM w P1A (zachowane z Aneksu B oryginalnego raportu)
Workspace | dm_model | Nowy parametr (≤1) | Motywacja fizyczna (rdzeń) | Zasada implementacji (przyjazna audytowi) |
|---|---|---|---|---|
DM_RAZOR | NFW (stałe c–M, bez rozrzutu) | — | Minimalna, audytowalna baza halo LambdaCDM; używana jako ścisłe porównanie z EFT | Stałe wspólne odwzorowanie; ścisły rejestr parametrów; używana tylko jako baza porównania względnego |
DM_RAZOR_SCAT | NFW + rozrzut c–M (legacy) | σ_logc | Relacja c–M ma rozrzut; przybliżona jednoparametrowym rozrzutem log-normalnym | ≤1 nowy parametr; nadal używa wspólnego odwzorowania; zysk domknięcia jest kryterium akceptacji |
DM_RAZOR_AC | NFW + kontrakcja adiabatyczna (legacy) | α_AC | Napływ barionów może powodować adiabatyczną kontrakcję halo; przybliżoną jednoparametrową siłą | ≤1 nowy parametr; odwzorowanie bez zmian; raportuje zmiany AICc/BIC i zysk domknięcia |
DM_RAZOR_FB | NFW + rdzeń feedbacku (legacy) | log r_core | Feedback może tworzyć wewnętrzny rdzeń; przybliżony jednoparametrową skalą rdzenia | ≤1 nowy parametr; ta sama rama domknięcia/kontroli negatywnej; poprawa RC-only nie jest jedynym celem |
DM_HIER_CMSCAT | Hierarchiczny rozrzut c–M + prior | σ_logc (hier) | Bardziej standardowe hierarchiczne c_i∼logN(c(M_i),σ_logc); wpływa na łączny posterior RC i GGL | Jawny prior; ukryte c_i zmarginalizowane; pozostaje niskowymiarowy i audytowalny |
DM_CORE1P | Jednoparametrowy proxy rdzenia (inspirowany coreNFW/DC14) | log r_core | Używa jednoparametrowego proxy rdzenia dla głównego efektu feedbacku barionowego, unikając wysokowymiarowych szczegółów historii formowania gwiazd | Cytuje standardową literaturę; ≤1 nowy parametr; powiązany z testem domknięcia |
DM_RAZOR_M | NFW + parametr nuisance kalibracji ścinania soczewkowego | m_shear (GGL) | Absorbuje kluczową systematykę po stronie słabego soczewkowania za pomocą parametru efektywnego, zmniejszając ryzyko traktowania systematyk jako fizyki | Nuisance jawnie zapisany; nie może oddziaływać zwrotnie na RC; wyniki oceniane głównie przez odporność domknięcia |
DM_STD | Standaryzowana baza DM (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Wnosi trzy najczęstsze zastrzeżenia do jednej, wciąż niskowymiarowej, standaryzowanej bazy | Raportuje rejestr parametrów i kryteria informacyjne razem; domknięcie jest główną metryką; używana jako najsilniejsze porównanie obronne DM |
Tabela B1 | Tabela wyników P1A (im więcej, tym lepiej; zachowana z Aneksu B oryginalnego raportu)
Gałąź modelu (workspace) | Δk | RC-only best logL_RC (Δ) | Siła domknięcia ΔlogL_closure (Δ) | Joint best logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Jak czytać tabelę B1 (tabelę wyników P1A) |
• Δk: nowo dodane stopnie swobody (większa wartość oznacza bardziej złożony model; większa złożoność nie oznacza automatycznie lepszego modelu). • Skup się na dwóch kolumnach: siła domknięcia ΔlogL_closure(Δ) (większa oznacza większą samospójność przenoszenia) oraz Joint best logL_total(Δ) (łączny wynik dopasowania). • Wartość w nawiasie, (Δ), to różnica względem DM_RAZOR, co ułatwia bezpośrednie porównanie. |
• Główne pytanie tej tabeli brzmi: czy przewaga domknięcia znika po „rozsądnym wzmocnieniu” bazy DM. • Wskazówka do lektury: DM_STD wyraźnie poprawia wynik łączny, ale jego siła domknięcia spada; EFT_BIN nadal pozostaje wyżej pod względem siły domknięcia. |
Jednym zdaniem: w tym niskowymiarowym, audytowalnym zestawie wzmocnień DM poprawa łącznego dopasowania nie wytwarza automatycznie silniejszego domknięcia; domknięcie, czyli przenoszalność, pozostaje kluczowym kryterium. |
7 | Jak czytać główne wyniki?
7.1 Dopasowanie łączne: przy spojrzeniu na oba zbiory danych wynik głównego porównania EFT jest wyższy
Tabela S1a i rycina S4 pokazują, że przy tych samych danych, tym samym wspólnym odwzorowaniu i w przybliżeniu tej samej skali parametrów rodzina EFT ma łączny ΔlogL_total równy 1155–1337 względem DM_RAZOR. Czytelnik ogólny może rozumieć to tak: według tej samej reguły punktacji zastosowanej łącznie do RC i GGL modele EFT z głównego porównania otrzymują wyższy wynik całkowity.
7.2 Test domknięcia: P1 najbardziej chce podkreślić „przenoszalność”
Wysoka siła domknięcia oznacza, że parametry wywnioskowane wyłącznie z RC potrafią lepiej przewidywać GGL bez ponownego patrzenia na GGL. W raporcie P1 ΔlogL_closure dla EFT wynosi 172–281, podczas gdy DM_RAZOR ma 127. Ten wynik jest ważniejszy niż stwierdzenie, że „każdy model dobrze dopasowuje własne dane”, ponieważ ogranicza swobodę modelu na drugim zbiorze danych.
7.3 Kontrola negatywna: dlaczego „załamanie sygnału” jest dobrą rzeczą?
Po losowym przetasowaniu w P1 odpowiedniości grup RC-bin→GGL-bin sygnał domknięcia EFT spada do zakresu 6–23. Dla czytelnika ogólnego ten krok jest jak kontrola antyoszustwa: gdyby przewaga domknięcia wynikała jedynie z kodu, jednostek, obsługi kowariancji albo przypadkowego dopasowania, mogłaby pozostać także przy przetasowanej odpowiedniości. Tymczasem rzeczywista przewaga się załamuje, co pokazuje, że zależy od poprawnego odwzorowania.
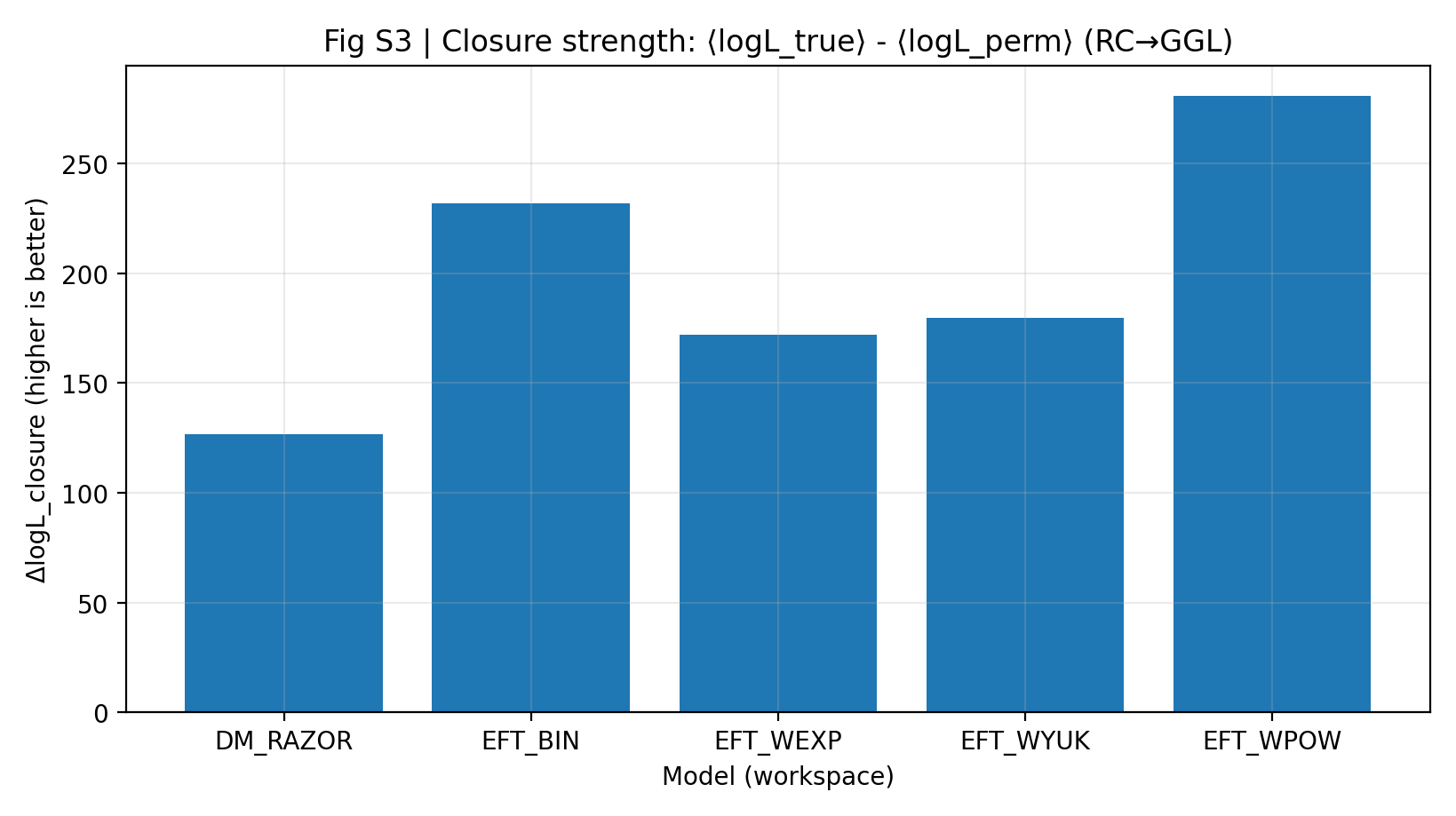
Rycina S3 | Siła domknięcia (im większa, tym lepiej): średnia przewaga logarytmu wiarygodności dla przewidywania RC-only → GGL.
Jak czytać tę rycinę |
Ta rycina jest rdzeniem P1. Im wyższy słupek, tym lepiej informacja nauczona z RC przenosi się na GGL. |
Rodzina EFT jest ogólnie wyżej niż DM_RAZOR, co wskazuje na silniejsze międzysondowe domknięcie EFT w eksperymencie „najpierw naucz się RC, potem przewiduj GGL”. |
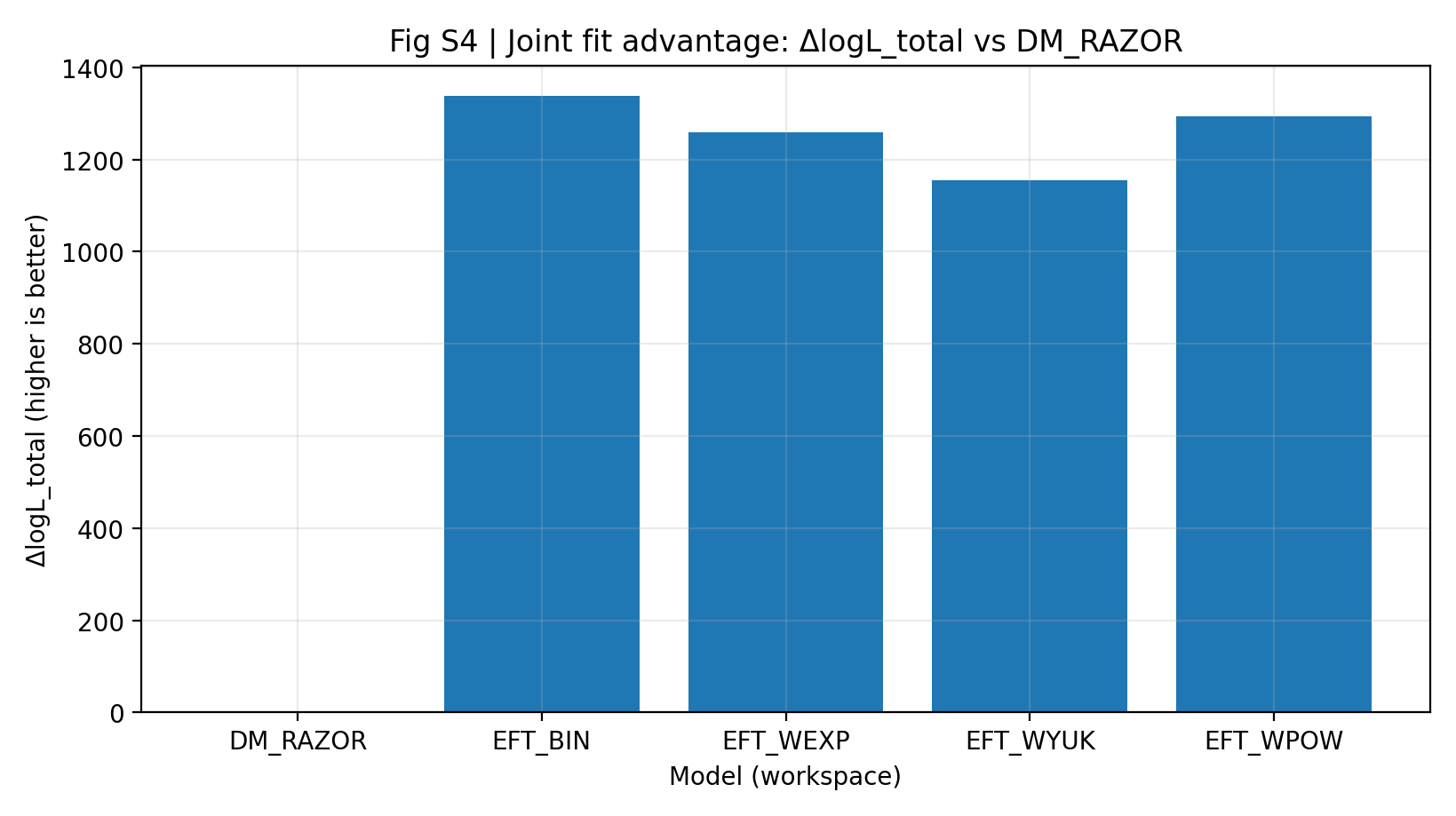
Rycina S4 | Przewaga dopasowania łącznego (im większa, tym lepiej): najlepsze logL_total dla RC+GGL względem DM_RAZOR.
Jak czytać tę rycinę |
Ta rycina pokazuje łączny wynik po połączeniu RC i GGL. |
Wszystkie modele EFT są znacznie powyżej 0, co wskazuje, że przewaga EFT w głównym porównaniu nie jest lokalnym efektem pojedynczego punktu, lecz ogólnym wzorcem w analizie łącznej. |
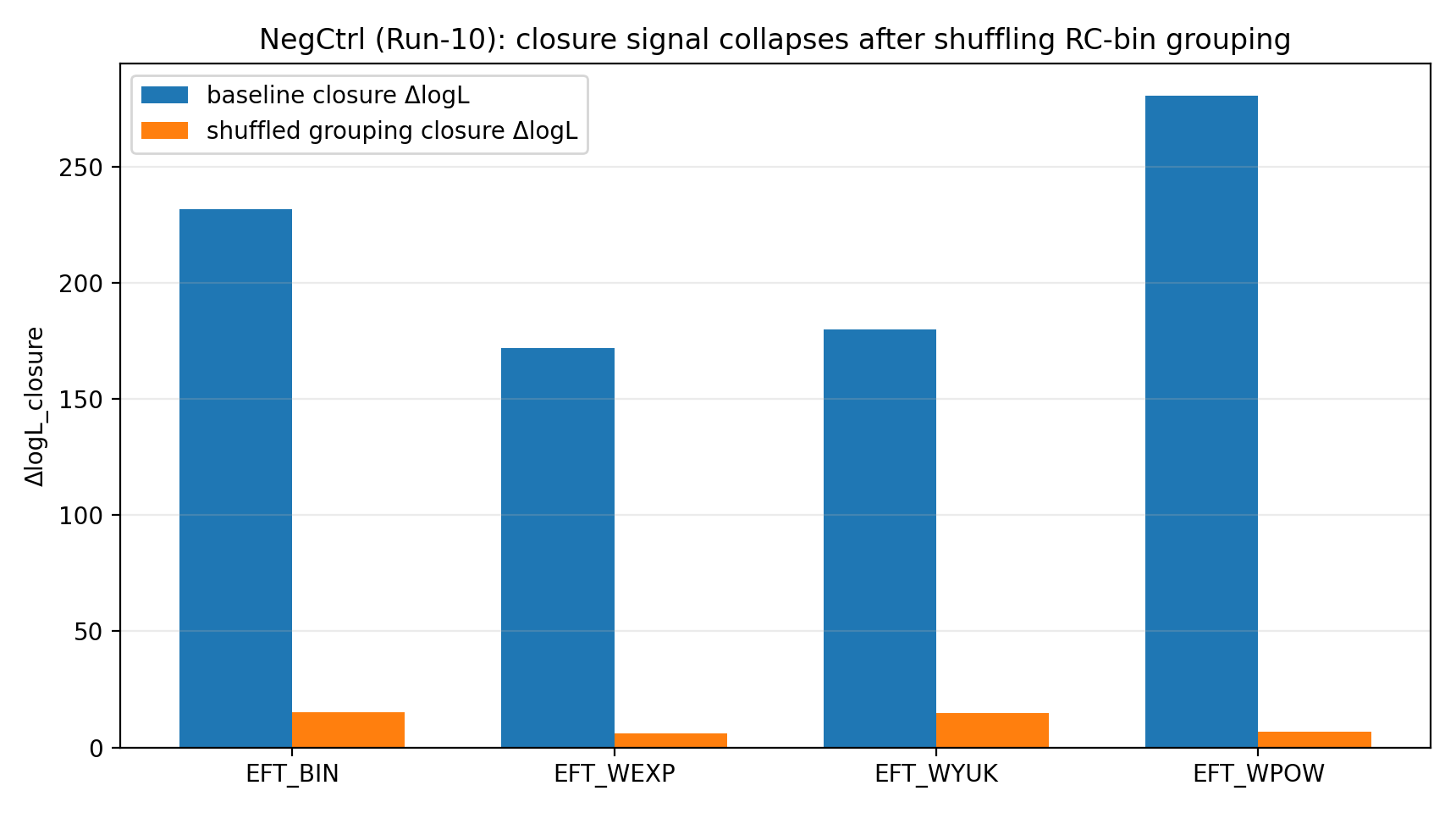
Rycina R1 | Kontrola negatywna: sygnał domknięcia gwałtownie spada po przetasowaniu grupowania.
Jak czytać tę rycinę |
Ta rycina pokazuje, że po zaburzeniu poprawnej relacji binowania RC↔GGL sygnał domknięcia gwałtownie spada. |
Dzięki temu wynik P1 wygląda bardziej jak rzeczywista spójność w odwzorowaniu między danymi niż jak numeryczny przypadek możliwy do uzyskania przy dowolnych odwzorowaniach. |
8 | Odporność i kontrole: jak P1 unika bycia „tylko efektownym dopasowaniem”?
Najłatwiejszy zarzut wobec raportu technicznego brzmi: czy przewaga nie wynika z jednego ustawienia szumu, jednego cięcia danych w obszarach centralnych, jednego sposobu traktowania kowariancji albo z przeuczenia? P1 odpowiada na to wieloma testami stresowymi.
Tabela 2 | Jak czytać testy odporności i kontrole negatywne w P1
Test | Obawa, którą ma wykluczyć | Jak go czytać |
Skan σ_int | Czy wniosek pozostaje stabilny, jeśli RC zawiera dodatkowy nieznany rozrzut? | Po rozluźnieniu błędów RC ranking i skala przewagi EFT pozostają stabilne. |
Skan R_min | Czy wniosek pozostaje stabilny, jeśli nie w pełni ufamy centralnym obszarom galaktyk? | Po przycięciu obszarów centralnych EFT nadal utrzymuje dodatnią przewagę. |
Skan cov-shrink | Czy wynik rankingu jest wrażliwy na niepewność estymacji kowariancji GGL? | Po skurczeniu kowariancji w kierunku macierzy diagonalnej przewaga nie jest wrażliwa. |
Drabina ablacji | Czy EFT polega na niepotrzebnej złożoności, aby wymusić dopasowanie? | Pełny EFT_BIN jest wspierany przez kryteria informacyjne. |
Predykcja LOO na wyłączonych danych | Czy model wyjaśnia tylko dane, które już widział? | Po wyłączeniu jednego binu GGL model nadal wykazuje silną zdolność generalizacji. |
Tasowanie binów RC | Czy domknięcie pochodzi z prawdziwego odwzorowania? | Domknięcie spada po przetasowaniu grupowania, co wspiera zależność od odwzorowania. |
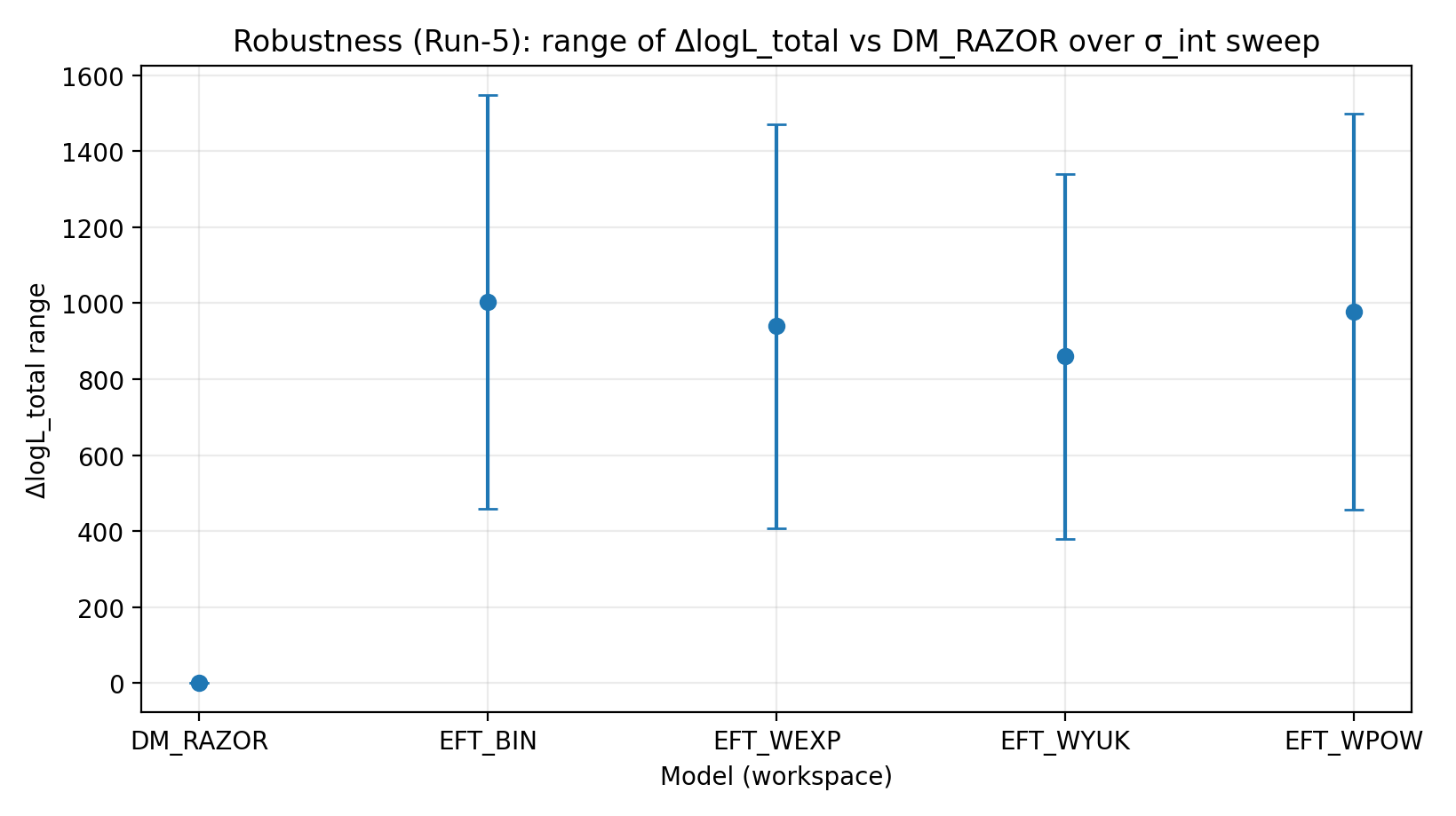
Rycina R2 | Zakres ΔlogL_total w skanie σ_int (im większa wartość, tym lepiej).
Jak czytać tę rycinę |
Testuje, czy prowadzenie EFT utrzymuje się po zmianach założonego wewnętrznego rozrzutu RC. |
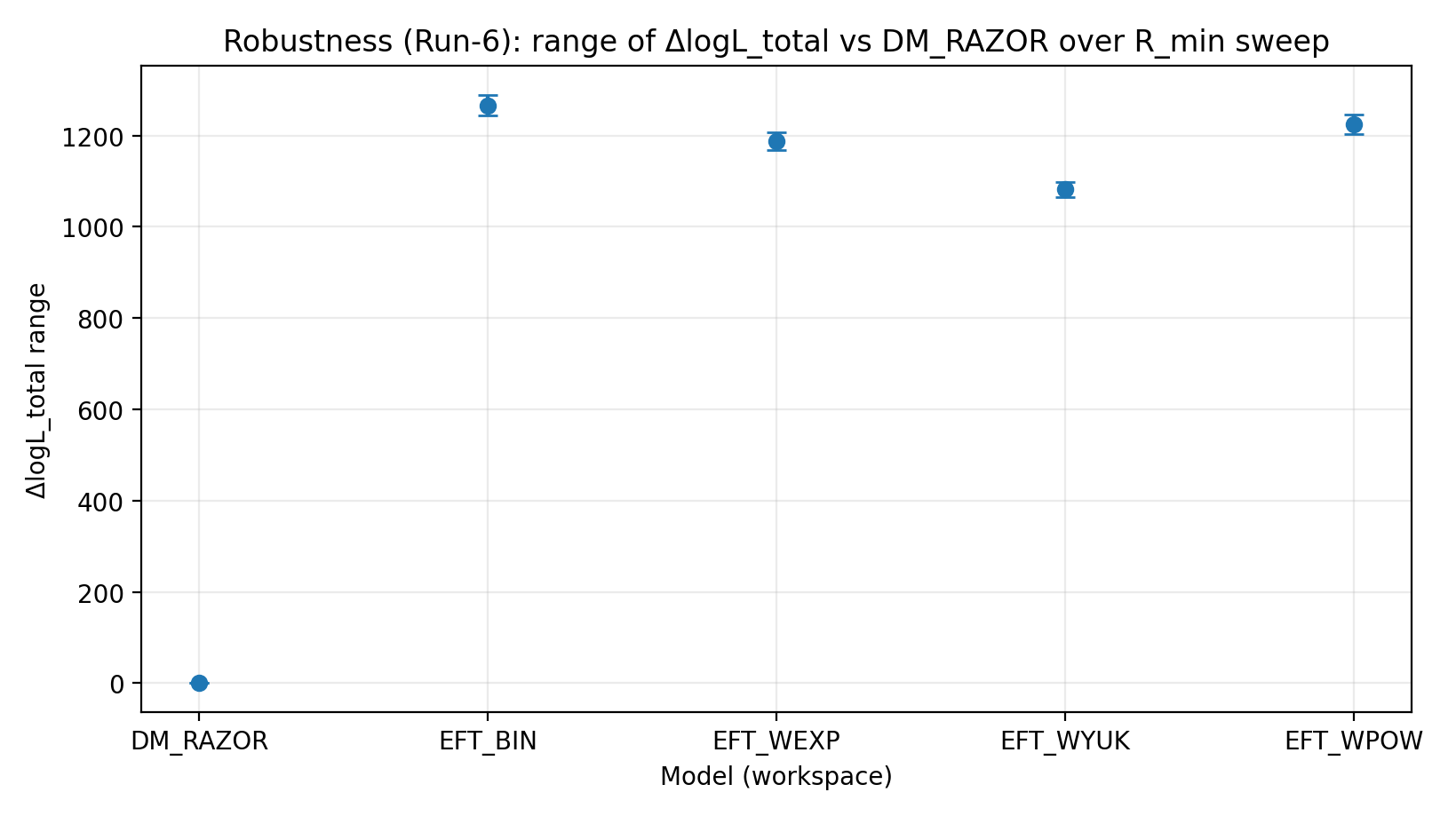
Rycina R3 | Zakres ΔlogL_total w skanie R_min (im większa wartość, tym lepiej).
Jak czytać tę rycinę |
Testuje, czy przewaga EFT pozostaje stabilna po przycięciu złożonych obszarów centralnych. |
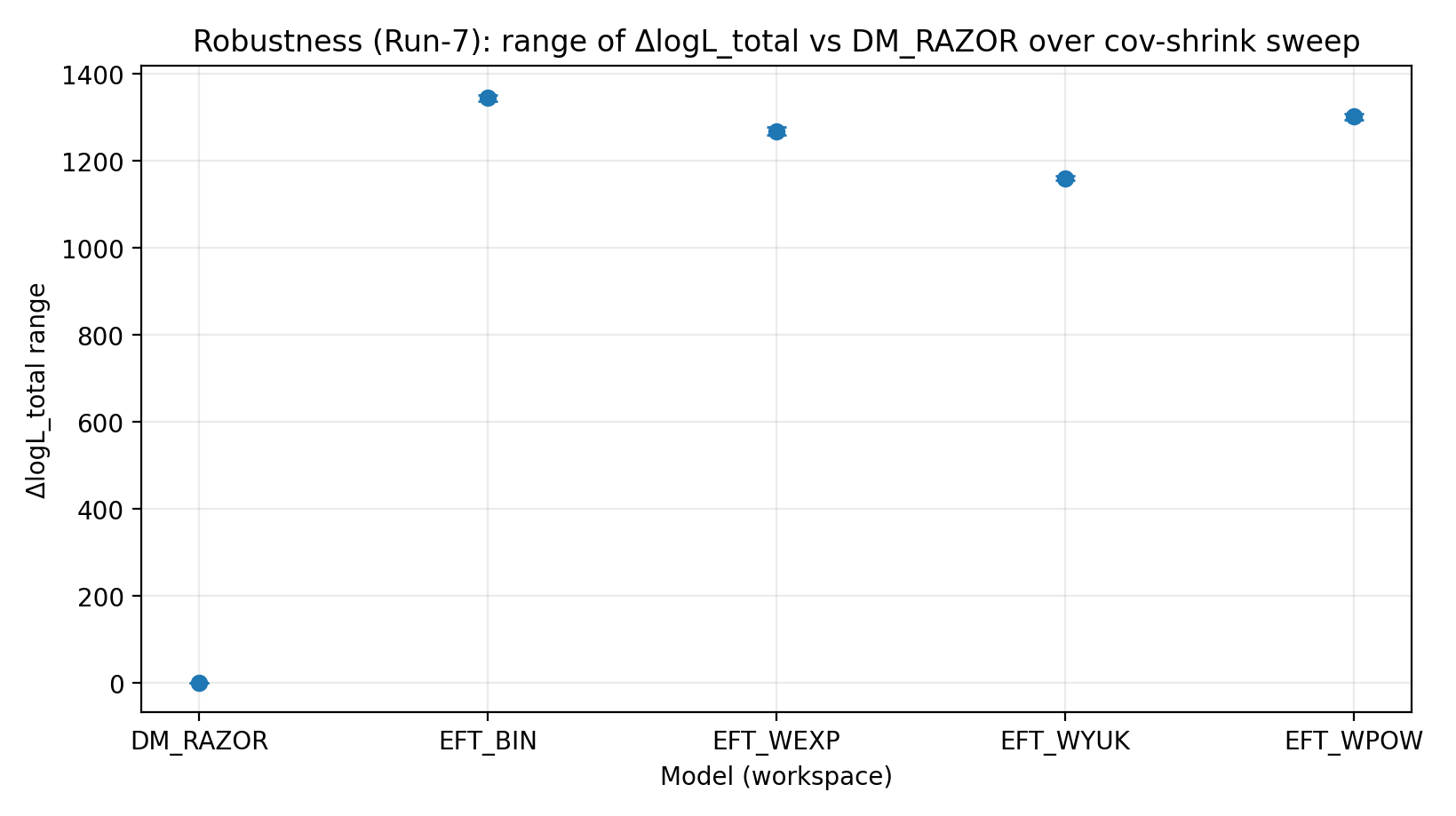
Rycina R4 | Zakres ΔlogL_total w skanie cov-shrink (im większa wartość, tym lepiej).
Jak czytać tę rycinę |
Testuje, czy ranking jest wrażliwy na zmiany sposobu traktowania kowariancji słabego soczewkowania. |
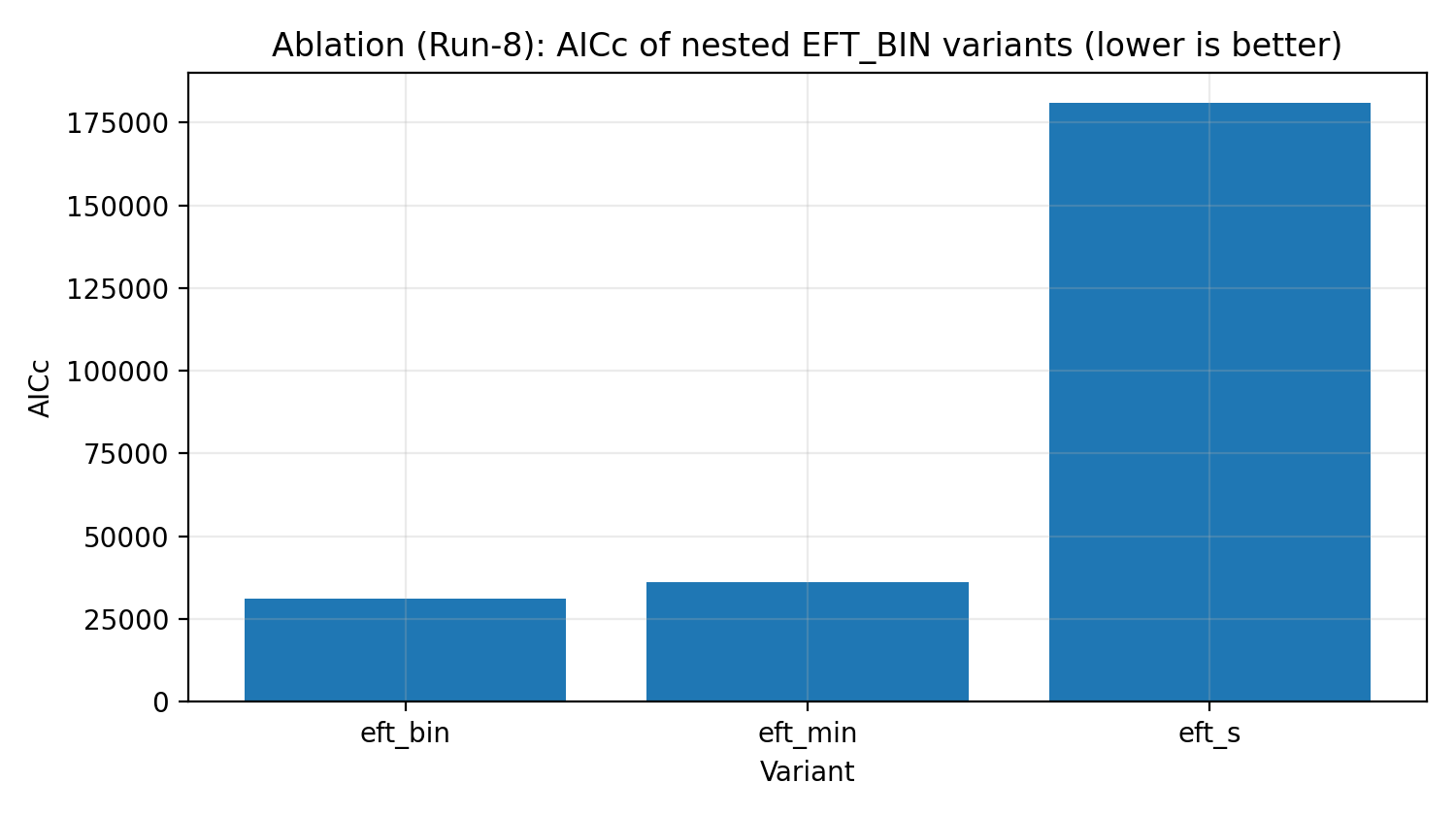
Rycina R5 | Drabina ablacji EFT_BIN (AICc, im mniej, tym lepiej).
Jak czytać tę rycinę |
Testuje, czy pełny EFT_BIN jest potrzebny do wyjaśnienia danych, a nie tylko dodaje zbędne parametry. |
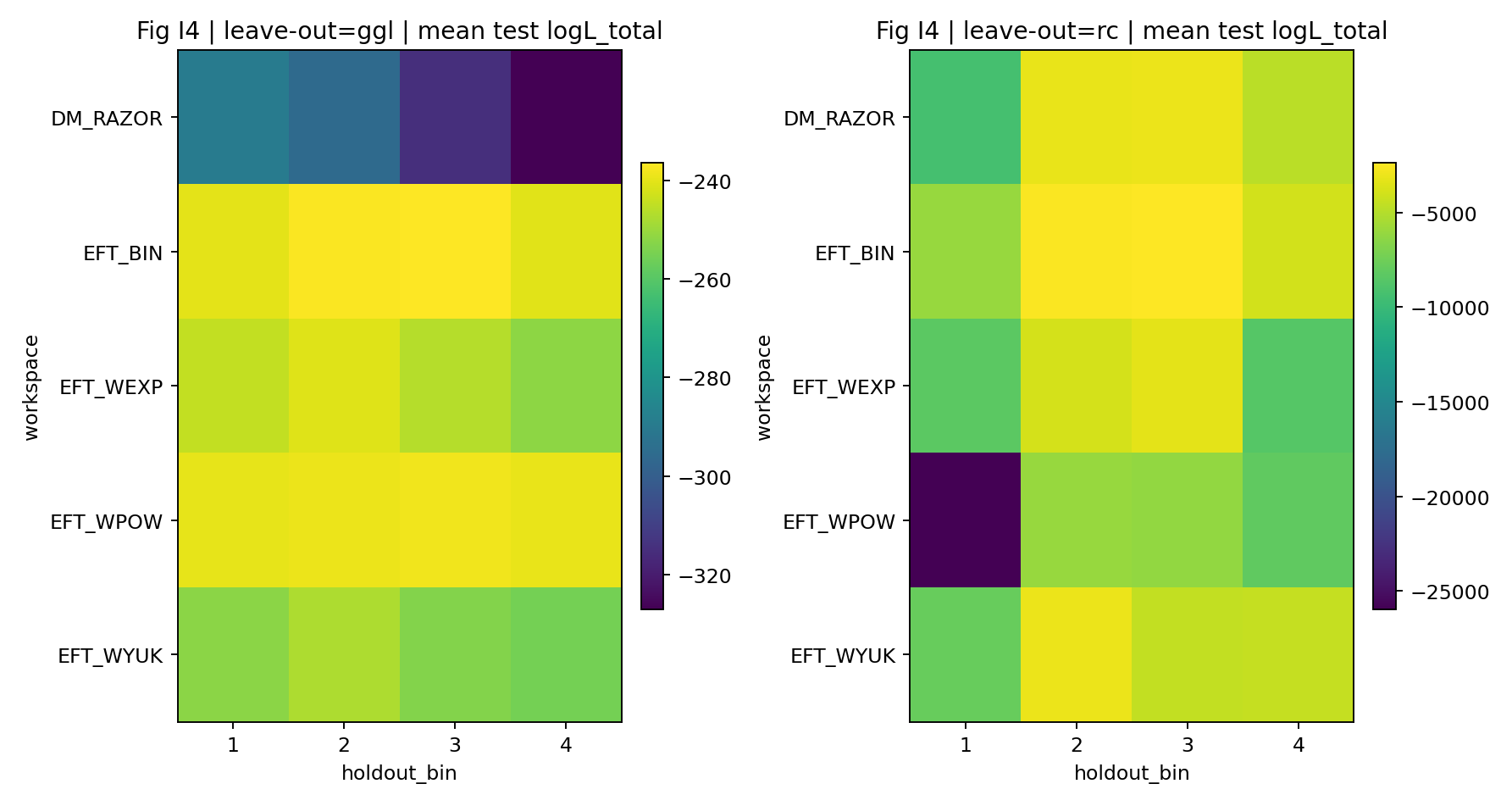
Rycina R6 | LOO: rozkład logarytmu wiarygodności dla wyłączonych binów.
Jak czytać tę rycinę |
Testuje, czy model nadal ma zdolność predykcyjną na niewidzianych binach GGL. |
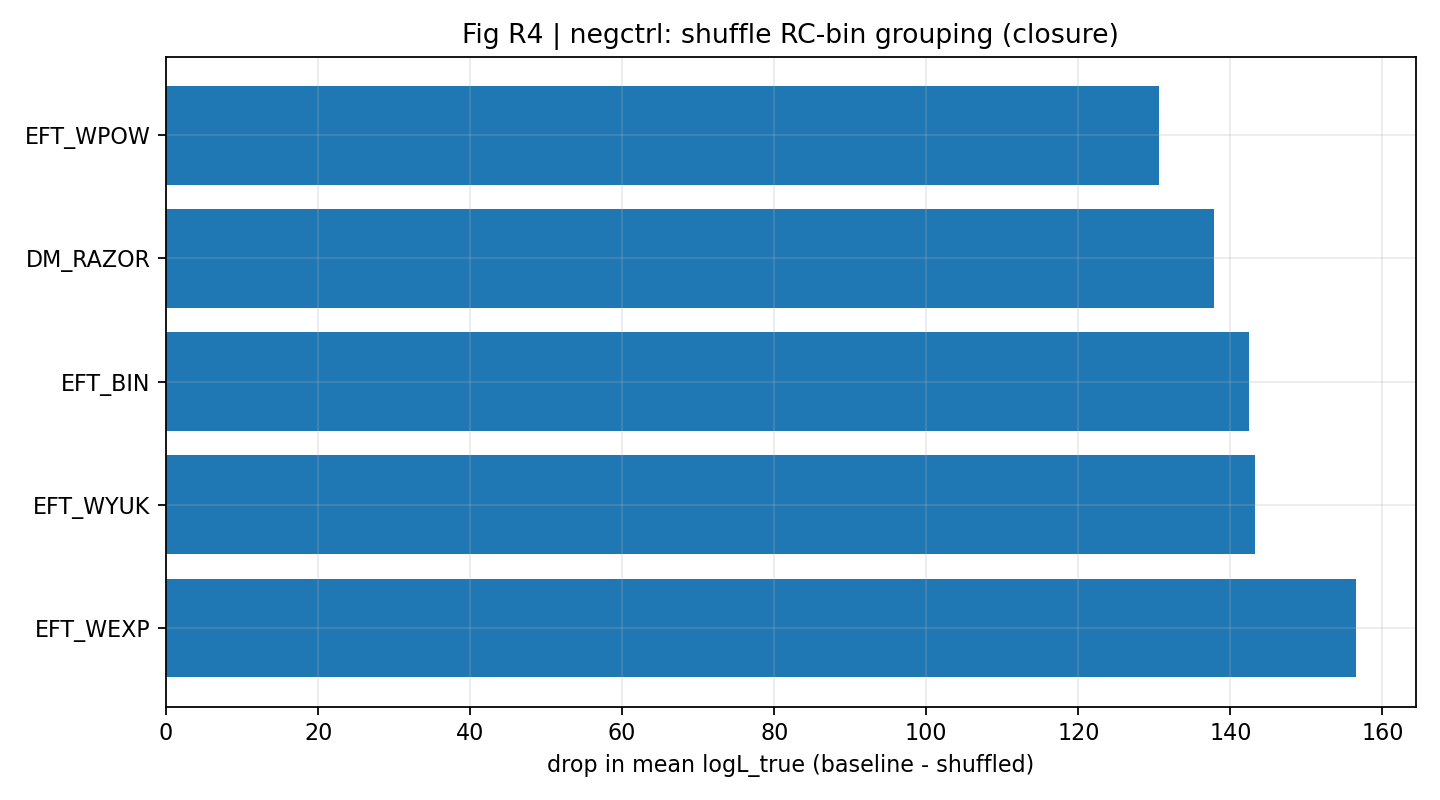
Rycina R7 | Kontrola negatywna: przetasowane odwzorowanie powoduje wyraźny spadek średniego logL_true domknięcia.
Jak czytać tę rycinę |
Dodatkowo pokazuje, z perspektywy średniego logL_true, że domknięcie zależy od poprawnego odwzorowania między danymi. |
9 | P1A: dlaczego „wiele modeli DM w aneksie” jest kluczową korektą
Ta sekcja nie pyta: „Czy EFT pokonała tylko jedną minimalną bazę DM_RAZOR?”. Pyta, czy wnioski z testu domknięcia i dopasowania łącznego zmieniają się, gdy baza DM zostaje wzmocniona w niskowymiarowym, odtwarzalnym i jasno zapisanym rejestrze parametrów (P1A). Innymi słowy, P1A ma zmniejszyć zarzut, że „wybrano jedynie zbyt słabą bazę DM”, i przenieść dyskusję ku pytaniu, czy zachowanie domknięcia nadal różni się przy zestawie audytowalnych wzmocnień DM.
P1A nie ma wyczerpać wszystkich możliwych sposobów modelowania halo LambdaCDM ani nie zamienia strony DM w wysokowymiarowy, nieaudytowalny dopasowywacz. Wybiera niskowymiarowe, odtwarzalne wzmocnienia z jasnym rejestrem parametrów: rozrzut koncentracji, kontrakcję adiabatyczną, rdzeń feedbacku, hierarchiczny prior rozrzutu c–M, jednoparametrowy proxy rdzenia, parametr nuisance kalibracji ścinania słabego soczewkowania oraz połączoną bazę DM_STD.
Główne odczytanie P1A |
Spośród trzech gałęzi legacy tylko feedback/core daje niewielki dodatni wzrost siły domknięcia; SCAT i AC nie dają zysku netto domknięcia. |
DM_HIER_CMSCAT, DM_RAZOR_M i DM_CORE1P mają bardzo mały wpływ na siłę domknięcia albo nie pokazują istotnej poprawy netto. |
DM_STD może znacząco poprawić łączny logL, ale jego siła domknięcia spada, co sugeruje, że poprawia głównie elastyczność dopasowania łącznego, a nie moc przewidywania transferowego RC→GGL. |
EFT_BIN nadal zachowuje wyższą siłę domknięcia i przewagę dopasowania łącznego w tabeli B1 P1A; dlatego rdzeniowej tezy P1 nie należy redukować do „pokonała tylko minimalny DM_RAZOR”. |
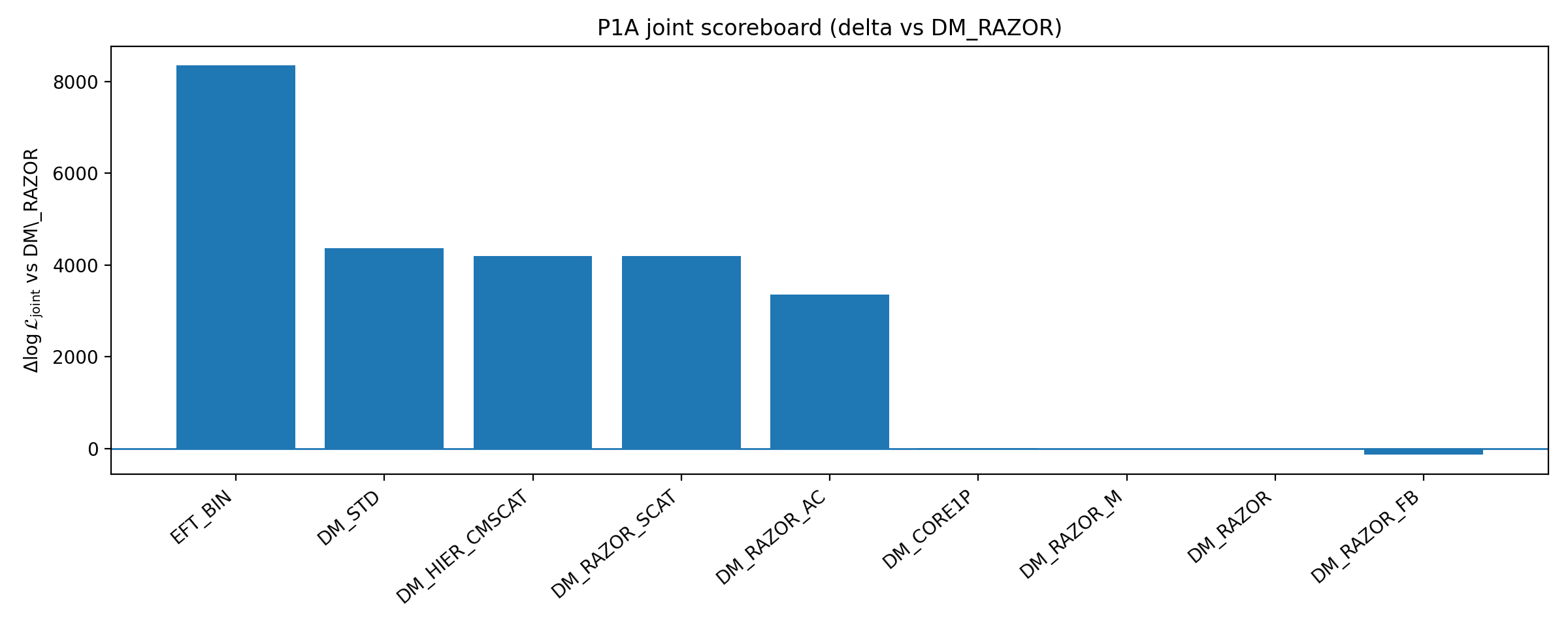
Rycina B1 | Tabela wyników P1A: ΔlogL domknięcia i łączne względem bazy (im więcej, tym lepiej).
Jak czytać tę rycinę |
Ta rycina pokazuje wyniki wielu gałęzi wzmocnienia DM względem bazy. |
Jej znaczenie nie brzmi „cała DM jest wykluczona”, lecz raczej: w obrębie niskowymiarowych, audytowalnych wzmocnień DM wybranych przez P1A wzmocnienie DM nie usuwa przewagi domknięcia EFT_BIN. |
10 | Dlaczego eksperyment P1 ma znaczenie
10.1 Znaczenie metodologiczne: umieszczenie „domknięcia między sondami” ponad „dopasowaniem jednej sondy”
Teoria skali galaktyk łatwo grzęźnie w pytaniu, czy dany model potrafi dopasować konkretny zestaw krzywych rotacji. P1 podnosi pytanie o poziom wyżej: czy parametry nauczone z RC potrafią przewidzieć słabe soczewkowanie bez ponownego dostrajania do GGL? To zmienia P1 z „konkursu dopasowań” w „test przewidywania transferowego”.
10.2 Znaczenie przejrzystości: potraktowanie łańcucha odtwarzalności jako części wyniku
Ważnym wkładem P1 jest wspólne opublikowanie danych, tabel i rycin, etykiet uruchomień, kontroli negatywnych, pakietu reprodukcyjnego i łańcucha audytu. Ma to znaczenie zarówno dla zwolenników, jak i krytyków: dyskusja może wracać do tych samych publicznych danych, tego samego odwzorowania, tych samych skryptów i tych samych metryk, zamiast porównywać hasła.
10.3 Znaczenie fizyczne: silny test stresowy dla kierunków „grawitacji bez ciemnej materii”
W kierunkach grawitacji bez ciemnej materii wiele modeli potrafi wyjaśnić część krzywych rotacji lub RAR. Trudniejsze zadanie polega na jednoczesnym przejściu odczytów słabego soczewkowania i pokazaniu w kontrolach negatywnych, że sygnał zależy od poprawnego odwzorowania. P1 jest ważny, ponieważ umieszcza średnią odpowiedź grawitacyjną EFT w protokole przypominającym egzamin zewnętrzny: RC jest polem treningowym, GGL polem transferu, a shuffle polem antyoszustwa.
10.4 Czy to ważny eksperyment dla dziedziny „grawitacji bez ciemnej materii”?
Ostrożnie mówiąc: jeżeli przetwarzanie danych P1, pakiet reprodukcyjny i protokół domknięcia utrzymają się pod zewnętrzną weryfikacją, to P1 można uznać za eksperyment domknięcia RC+GGL wart poważnego traktowania w kierunkach grawitacji bez ciemnej materii / grawitacji modyfikowanej. Jego znaczenie nie leży w haśle „ciemna materia została obalona”, lecz w dostarczeniu międzysondowego kryterium, które można odtworzyć, zakwestionować i rozszerzyć.
Czy istnieją już frameworki predykcyjnego domknięcia RC+GGL na tym samym poziomie? |
Istnieją powiązane frameworki i tradycje obserwacyjne: MOND/RAR dobrze porządkuje wiele zjawisk krzywych rotacji; praca KiDS-1000 nad RAR ze słabego soczewkowania również porównywała MOND, emergent gravity Verlindego i modele LambdaCDM; LambdaCDM także może wyjaśniać część zjawisk soczewkowych/dynamicznych przez relacje galaktyka–halo, halo gazowe i modelowanie feedbacku. |
Jednak precyzyjna teza P1 nie brzmi: „żaden inny framework na świecie nie potrafi wyjaśnić RC+GGL”. Brzmi raczej: w ramach własnego publicznego protokołu P1 — stałego odwzorowania, domknięcia RC-only→GGL, kontroli negatywnej shuffle, rejestru parametrów i wielomodelowych testów stresowych DM w P1A — EFT raportuje silniejsze domknięcie. |
Innymi słowy, częścią P1 najbardziej wartą zewnętrznego testowania jest konkretny, odtwarzalny protokół porównawczy. Bardzo wartościowym następnym krokiem byłoby sprawdzenie, czy MOND/RAR, LambdaCDM/HOD, symulacje hydrodynamiczne lub inne frameworki grawitacji modyfikowanej mogą osiągnąć takie same albo wyższe wyniki domknięcia w tym samym protokole. |
11 | Co P1 może wnioskować, a czego nie może wnioskować?
Tabela 3 | Granice wniosków P1
Można wnioskować | W danych RC+GGL P1, przy stałym odwzorowaniu i głównym protokole porównawczym, rodzina EFT ma wyższe wyniki dopasowania łącznego i większą siłę domknięcia niż minimalny DM_RAZOR. |
Można wnioskować | W niskowymiarowym, audytowalnym zakresie wzmocnień DM w P1A wiele wzmocnień DM nie usuwa przewagi domknięcia EFT_BIN. |
Można wnioskować | Kontrola negatywna shuffle pokazuje, że sygnał domknięcia zależy od poprawnego odwzorowania między danymi i nie jest osiągalny przy dowolnych odwzorowaniach. |
Nie można wnioskować | Nie można powiedzieć, że P1 obalił wszystkie modele ciemnej materii. P1A nadal nie wyczerpuje niesferyczności, zależności środowiskowych, złożonych relacji galaktyka–halo, wysokowymiarowego feedbacku ani pełnych symulacji kosmologicznych. |
Nie można wnioskować | Nie można powiedzieć, że kompletny framework EFT został udowodniony od pierwszych zasad. P1 testuje tylko fenomenologiczną warstwę średniej odpowiedzi grawitacyjnej. |
Nie można wnioskować | Nie można powiedzieć, że wykluczono wszystkie systematyki. P1 dostarcza dowodów odporności tylko w ramach wymienionych testów stresowych i zakresu audytu. |
12 | Najczęstsze pytania czytelników ogólnych
Q1: Czy to znaczy, że „ciemna materia nie istnieje”?
Nie. Wnioski P1 muszą być ograniczone do danych, protokołu i modeli porównawczych użytych tutaj. P1A wychodzi poza minimalny DM_RAZOR, ale nadal nie reprezentuje wszystkich możliwych modeli ciemnej materii.
Q2: Czy to znaczy, że „EFT została udowodniona”?
Również nie. P1 testuje EFT jako parametryzację średniej odpowiedzi grawitacyjnej i pokazuje silniejszy wynik w domknięciu RC→GGL; mechanizm mikroskopowy i pełna teoria nie są wnioskiem P1.
Q3: Dlaczego nie podać bezpośrednio poziomu istotności w σ?
P1 używa jednolitych wyników wiarygodności, kryteriów informacyjnych i różnic domknięcia. ΔlogL jest względną przewagą według tej samej reguły punktacji; nie jest równoważny pojedynczej wartości σ.
Q4: Dlaczego tasować RC-bin→GGL-bin?
To kontrola negatywna. Prawdziwy sygnał między sondami powinien zależeć od poprawnego odwzorowania; gdyby po przetasowaniu pozostał równie silny, sugerowałoby to raczej możliwe obciążenie implementacyjne albo statystyczny sygnał fałszywy.
Q5: Co P1 powinien zrobić dalej?
Rozszerzyć ten sam protokół na więcej danych, więcej porównań DM, bardziej złożone systematyki i więcej frameworków grawitacji modyfikowanej — zwłaszcza w sposób, który pozwoli zespołom zewnętrznym ponownie testować wyniki przy tej samej metryce domknięcia.
13 | Mini-słownik
Tabela 4 | Mini-słownik
Termin | Wyjaśnienie w jednym zdaniu |
Krzywa rotacji (RC) | Relacja promień–prędkość rotacji w dysku galaktyki, używana do wnioskowania o efektywnej grawitacji wewnątrz dysku. |
Słabe soczewkowanie (GGL) | Miara średniego rozkładu grawitacji/masy wokół galaktyk pierwszego planu poprzez statystyczne zniekształcenie kształtów galaktyk tła. |
Test domknięcia | Używa posteriori RC do przewidywania GGL, a następnie porównuje wynik z kontrolą negatywną uzyskaną przez przetasowane odwzorowanie. |
Kontrola negatywna | Celowo łamie kluczową strukturę, aby sprawdzić, czy sygnał znika; służy do wykluczania sygnałów fałszywych. |
Halo NFW | Profil gęstości halo ciemnej materii powszechnie używany w modelach zimnej ciemnej materii. |
Relacja c–M | Relacja między koncentracją c halo ciemnej materii a masą M; dopuszczenie rozrzutu wpływa na elastyczność modelu. |
DM_STD | Standaryzowana gałąź testu stresowego DM w P1A, łącząca wiele niskowymiarowych wzmocnień DM i parametr nuisance soczewkowania. |
ΔlogL | Różnica logarytmu wiarygodności między dwoma modelami według tej samej reguły punktacji; wartość dodatnia oznacza, że pierwszy model jest lepszy. |
Kowariancja | Macierzowy opis korelacji między punktami danych; dane słabego soczewkowania zwykle wymagają pełnej kowariancji. |
14 | Sugerowana ścieżka lektury i wejścia cytowania
1. Najpierw przeczytaj sekcje 0–2 tego przewodnika, aby ustalić problem P1 i celowo oszczędną rolę EFT w P1.
2. Następnie zobacz rycinę S3, rycinę S4 oraz tabele S1a/S1b, aby zrozumieć siłę domknięcia, dopasowanie łączne i kontrole negatywne.
3. Jeżeli martwi Cię, że „baza DM jest zbyt słaba”, przejdź bezpośrednio do sekcji 9 oraz tabeli B1 / ryciny B1.
4. W celu weryfikacji technicznej wróć do raportu technicznego P1 v1.1, suplementu Tables & Figures Supplement oraz full_fit_runpack.
Główne punkty wejścia do archiwów |
Raport techniczny P1 (poziom wydania, Concept DOI): 10.5281/zenodo.18526334 |
Pełny pakiet reprodukcyjny P1 (Concept DOI): 10.5281/zenodo.18526286 |
Strukturalna baza wiedzy EFT (opcjonalnie, Concept DOI): 10.5281/zenodo.18853200 |
Uwaga licencyjna: raport techniczny używa CC BY-NC-ND 4.0; pełny pakiet reprodukcyjny używa CC BY 4.0 (za autorytatywne należy uznać raport techniczny i archiwa Zenodo). |
15 | Bibliografia i zewnętrzne tło
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.