P1_RC_GGL: Ścisły test domknięcia dynamiki galaktyk i słabego soczewkowania (krzywe rotacji + GGL)
Ramy średniej grawitacji EFT kontra minimalna linia bazowa NFW dla zimnej ciemnej materii (DM)
Zapoznaj się z oryginalnym raportem z ewaluacji:
1. ChatGPT: https://chatgpt.com/share/6a00cd62-6e34-83eb-b165-6ec09e3519cc
2. Gemini: https://gemini.google.com/share/773ec96d75a0
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_c0b4fa65-0e86-4adb-9b58-5617d616dc04
4. Qwen: https://chat.qwen.ai/s/22ab9336-671f-420a-a7fa-43e24774bb2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/tj6k7hb5owtoldg2bm
0 Streszczenie wykonawcze
Niniejszy raport jest zdeponowaną w Zenodo archiwalną wersją publikacyjną. Zapewnia zintegrowany, audytowalny łańcuch obejmujący dane, księgę modeli, uczciwe porównanie, test domknięcia oraz materiały reprodukcyjne. Dodatek B (P1A) pełni funkcję uzupełniającego testu odporności. Koncentruje się na testach obciążeniowych typu „bardziej standardowa linia bazowa DM + jedna kluczowa systematyka soczewkowania”, służących ocenie wrażliwości głównych wniosków na bardziej realistyczne modelowanie DM i obsługę systematyk soczewkowania.
Główne wnioski (cztery zdania nadające się do bezpośredniego cytowania; zob. sekcję 2.4):
(1) W dopasowaniu krzywych rotacji (RC) rodzina EFT znacząco przewyższa DM_RAZOR we wszystkich kombinacjach jąder i priorytetów; typowa poprawa wynosi Δlog𝓛_RC ≈ 10^3 (zob. tabela S1a).
(2) W teście domknięcia RC→GGL EFT wykazuje silniejszą przenoszalność między sondami: siła domknięcia Δlog𝓛_closure (True−Perm) jest istotnie wyższa niż dla DM_RAZOR, a różnica pozostaje odporna na skany kurczenia kowariancji, R_min i σ_int (zob. rys. S3 i tabela S1b).
(3) W dopasowaniu wspólnym (RC+GGL) EFT utrzymuje stabilną przewagę; w kontroli negatywnej, która niszczy wspólne odwzorowanie, przewaga ta załamuje się, co wspiera interpretację, że „efekt średniej grawitacji” pochodzi ze wspólnego odwzorowania, a nie z przypadkowego dopasowania (zob. rys. S4).
(4) Bez istotnego zwiększania wymiarowości Dodatek B (P1A) poddaje stronę DM testom obciążeniowym z użyciem bardziej standardowych modułów linii bazowej DM oraz jednej kluczowej zmiennej nuisance systematyki soczewkowania. Te wzmocnienia nie usuwają przewagi domknięcia EFT (zob. tabela B1 i rys. B1).
Dostępność danych i kodu: Concept DOI raportu 10.5281/zenodo.18526334; Concept DOI pełnego pakietu reprodukcyjnego 10.5281/zenodo.18526286. Tagi odpowiadające Dodatkowi B (P1A) to run_tag=20260213_151233, closure_tag=20260213_161731 oraz joint_tag=20260213_195428.
1 Abstrakt
Przeprowadzamy replikowalne porównanie ilościowe dwóch ram teoretycznych na tych samych danych i w ramach tego samego protokołu statystycznego: modelu „korekty średniej grawitacji” proponowanego przez Teorię Włókna Energii (EFT; odrębną od powszechnego skrótu effective field theory) oraz bazowego modelu halo NFW dla zimnej ciemnej materii (DM_RAZOR). DM_RAZOR celowo wybrano jako „minimalną linię bazową DM”: halo NFW ze stałą relacją c–M (bez rozrzutu między halo), służące jako audytowalna i reprodukowalna kontrola. Należy także podkreślić, że niniejsza praca traktuje EFT jako fenomenologiczną, MOND-podobną parametryzację pola efektywnego / odpowiedzi efektywnej do testowania w jednolitym protokole statystycznym, a nie jako wyprowadzenie jej mikroskopowych pierwszych zasad w ramach tej pracy.
Dane obejmują 2295 punktów prędkości z krzywych rotacji SPARC (RC), jednolicie wstępnie przetworzonych i zbinowanych (104 galaktyki, 20 koszyków RC), wraz z nadmiarową gęstością powierzchniową ΔΣ(R) ze słabego soczewkowania galaktyka–galaktyka KiDS-1000 (GGL) (4 koszyki masy gwiazdowej × 15 punktów R na koszyk, łącznie 60 punktów, z wykorzystaniem pełnej kowariancji).
Kolejno wykonujemy inferencję tylko z RC, test domknięcia RC→GGL, inferencję tylko z GGL oraz wspólną inferencję RC+GGL, stosując audyty spójności, aby każda cytowana wartość liczbowa była możliwa do prześledzenia. Przy ścisłej księdze parametrów i ograniczeniach wspólnego odwzorowania (DM: 20 parametrów log M200_bin; EFT: 20 parametrów log V0_bin + 1 globalny log ℓ) rodzina EFT znacząco przewyższa DM_RAZOR w dopasowaniu wspólnym: ΔlogL_total = 1155–1337 względem DM_RAZOR. Co ważniejsze, test domknięcia pokazuje, że posterior RC ma nietrywialną moc predykcyjną dla GGL: siła domknięcia EFT wynosi ΔlogL_closure = 172–281, więcej niż 127 dla DM_RAZOR. Gdy grupowanie RC-bin→GGL-bin zostaje losowo przetasowane, sygnał domknięcia spada do 6–23, co potwierdza, że nie jest on przypadkiem statystycznym ani artefaktem implementacji. W systematycznych skanach σ_int, R_min i kurczenia kowariancji względna przewaga EFT pozostaje dodatnia i stabilna co do skali. Aby odpowiedzieć na częste zastrzeżenia, że „linia bazowa DM jest zbyt słaba” albo że „systematyki są mylone z fizyką”, Dodatek B (P1A) przedstawia bardziej standardowy, a zarazem nadal niskowymiarowy i audytowalny test obciążeniowy linii bazowej DM, obejmujący hierarchiczny rozrzut c–M + prior, jednoparametrowy proxy jądra, soczewkowanie m oraz model łączony DM_STD. W tym samym protokole domknięcia wzmocnienia te nie usuwają przewagi domknięcia EFT (zob. tabela B1 / rys. B1).
Słowa kluczowe: krzywe rotacji; słabe soczewkowanie galaktyka–galaktyka; test domknięcia; EFT; zimna ciemna materia; inferencja bayesowska
2 Wprowadzenie i przegląd wyników
Krzywe rotacji (RC) i słabe soczewkowanie galaktyka–galaktyka (GGL) są dwiema komplementarnymi sondami grawitacyjnymi: RC ograniczają potencjał dynamiczny i relację przyspieszenia radialnego (RAR) w płaszczyźnie dysku, natomiast GGL mierzy rzutowany rozkład masy i odpowiedź grawitacyjną w skali halo. Dla każdej teorii kandydującej kluczowe pytanie nie brzmi, czy potrafi ona osobno dopasować oba zbiory danych, lecz czy potrafi wyjaśnić je spójnie przy tym samym odwzorowaniu między danymi i tych samych wspólnych ograniczeniach.
Dlatego niniejsza praca przyjmuje „test domknięcia” jako główny protokół statystyczny: najpierw posterior z samego RC służy do predykcji GGL w przód, a następnie porównuje się go z kontrolą negatywną, w której odwzorowanie RC-bin→GGL-bin zostaje permutowane/przetasowane. Pozwala to ocenić przenoszalność predykcji między danymi i wykluczyć fałszywe sygnały wynikające z błędów implementacji lub przypadkowego dopasowania.
Pozycjonowanie teoretyczne i zakres: praca ta nie próbuje przedstawić mikroskopowego wyprowadzenia EFT (Energy Filament Theory) z pierwszych zasad ani relatywistycznie kompletnego sformułowania. Traktujemy EFT jako niskowymiarową, MOND-podobną parametryzację pola efektywnego / odpowiedzi efektywnej (opisaną przez jądro f(x) i globalną skalę ℓ) i testujemy jej spójność między danymi oraz przenoszalną moc predykcyjną za pomocą testu domknięcia RC→GGL w ramach ścisłej księgi parametrów.
Program badawczy i deklaracja zakresu: niniejsza praca jest częścią trwającego programu odzysku obserwacyjnego serii P. W istniejących danych w skali galaktyk szukamy dwóch możliwych efektywnych wkładów tła: (i) „podłoża średniej grawitacji”, opisywalnego przez gruboziarnistą średnią odpowiedź grawitacyjną, oraz (ii) „podłoża stochastycznego/szumowego”, związanego z fluktuacjami procesów mikroskopowych. W tej pracy (P1) skupiamy się tylko na pierwszym z nich: bez wprowadzania hipotez dotyczących mikroskopowych mechanizmów wytwarzania używamy testu domknięcia RC→GGL, aby odzyskać obserwacyjne wskazania podłoża średniej grawitacji i porównać je z audytowalną linią bazową DM w jednolitym protokole kontrolnym. Jako heurystyczny obraz fizyczny: jeśli istnieją krótkotrwałe stopnie swobody, ich rozpad/anihilacja może przekształcać masę spoczynkową w energię-pęd niesione przez inne stopnie swobody, co na poziomie efektywnym naturalnie odpowiada rozkładowi „wkład średni + wkład fluktuacyjny”; niniejsza praca nie modeluje jednak tego obrazu mikroskopowego ilościowo.
Aby uniknąć nadinterpretacji, granice zakresu tej pracy są następujące:
• Co robi ta praca: przy ścisłych ograniczeniach księgi parametrów i wspólnego odwzorowania używa testu domknięcia do pomiaru przenoszalności predykcji między danymi oraz przeprowadza reprodukowalne porównanie między odpowiedzią średniej grawitacji EFT a linią bazową DM.
• Czego ta praca nie robi: nie omawia mikroskopowych mechanizmów wytwarzania, obfitości/czasów życia ani ograniczeń kosmologicznych; nie modeluje członu stochastycznego odpowiadającego „podłożu szumu”.
• Czego ta praca nie twierdzi: nie ma na celu obalenia ciemnej materii; P1 nie dostarcza ostatecznego werdyktu w sprawie istnienia „podłoża”, lecz raportuje dowody na poziomie etapu — że w wybranej tutaj odpornej domenie pomiarowej dane faworyzują modele zawierające średnią odpowiedź grawitacyjną.
Jednocześnie jasno stwierdzamy, że DM_RAZOR reprezentuje jedynie minimalną i audytowalną linię bazową NFW (stałe c–M i brak rozrzutu; brak kontrakcji adiabatycznej, jądra feedbacku, niesferyczności oraz członów środowiskowych). Wniosek główny tekstu zasadniczego jest więc ściśle ograniczony do tego stwierdzenia: przy minimalnej linii bazowej oraz ścisłych ograniczeniach księgi parametrów i odwzorowania EFT wykazuje silniejszą spójność między danymi. Aby odpowiedzieć na częste pytanie, czy bardziej standardowa linia bazowa ΛCDM i modelowanie kluczowych systematyk soczewkowania istotnie zmieniłyby wniosek, w Dodatku B (P1A: test obciążeniowy standaryzacji linii bazowej DM) zbieramy bardziej standardowe, a zarazem nadal niskowymiarowe i audytowalne wzmocnienia DM oraz zmienną nuisance po stronie soczewkowania, zachowując dokładnie to samo wspólne odwzorowanie i protokół testu domknięcia jak w tekście głównym (zob. tabela B1 / rys. B1).
2.1 Tabele S1a–S1b: podsumowanie kluczowych metryk (ścisłe)
Tabela S1a przedstawia główne metryki porównawcze dla dopasowania wspólnego (RC+GGL): logL, ΔlogL, AICc i BIC. Tabela S1b przedstawia metryki testu domknięcia i skanów odporności: domknięcie, negatywną kontrolę shuffle oraz zakresy skanów σ_int / R_min / cov-shrink. Wszystkie wartości pochodzą ze ścisłej tabeli zbiorczej Tab_Z1_master_summary i można je prześledzić pozycja po pozycji w pakiecie archiwum wydania.
Tabela S1a | Główne metryki porównania dopasowania wspólnego (RC+GGL, ścisłe).
Model (przestrzeń robocza) | Jądro W | k | Wspólne logL_total (najlepsze) | ΔlogL_total względem DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
Tabela S1b | Metryki domknięcia i odporności (ścisłe).
Model (przestrzeń robocza) | Domknięcie ΔlogL (true-perm) | ΔlogL kontroli negatywnej po shuffle | Zakres ΔlogL w skanie σ_int | Zakres ΔlogL w skanie R_min | Zakres ΔlogL w skanie cov-shrink |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
2.2 Rys. S3: siła domknięcia (RC-only → przewidywane GGL)
Siła domknięcia jest zdefiniowana jako ΔlogL_closure ≡ ⟨logL_true⟩ − ⟨logL_perm⟩: na próbkach posterior z samego RC przewiduje się GGL w przód i porównuje z kontrolą negatywną, w której odwzorowanie RC-bin→GGL-bin jest permutowane.
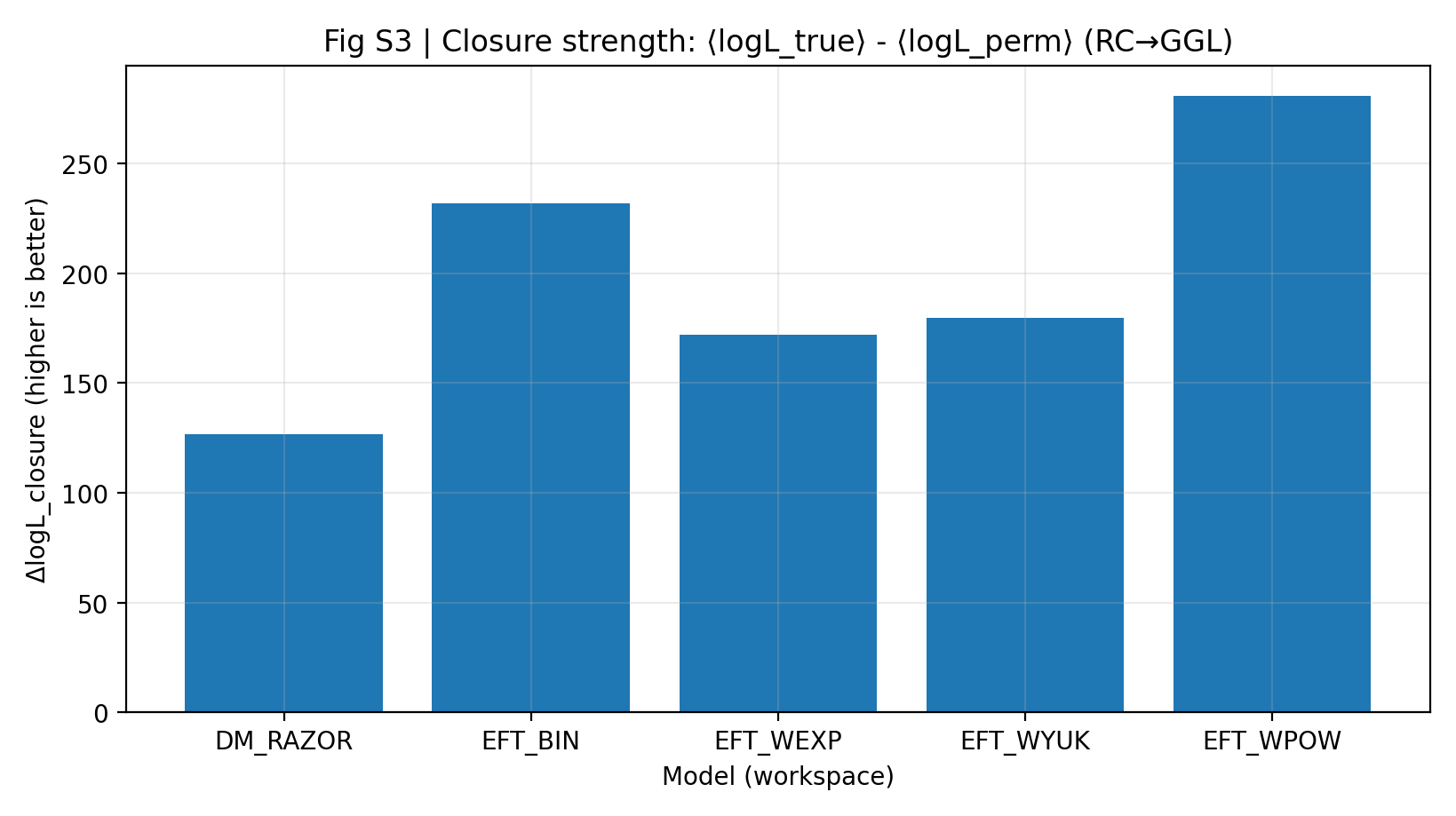
Rys. S3 | Siła domknięcia (więcej znaczy lepiej): przewaga średniej log-wiarygodności predykcji RC-only → GGL.
2.3 Rys. S4: główne porównanie dopasowania wspólnego (RC+GGL)
Przewagę dopasowania wspólnego definiujemy jako ΔlogL_total ≡ logL_total(model) − logL_total(DM_RAZOR). Przy tych samych danych, tym samym odwzorowaniu i niemal tej samej skali parametrów rodzina EFT osiąga znacząco wyższą wspólną log-wiarygodność.
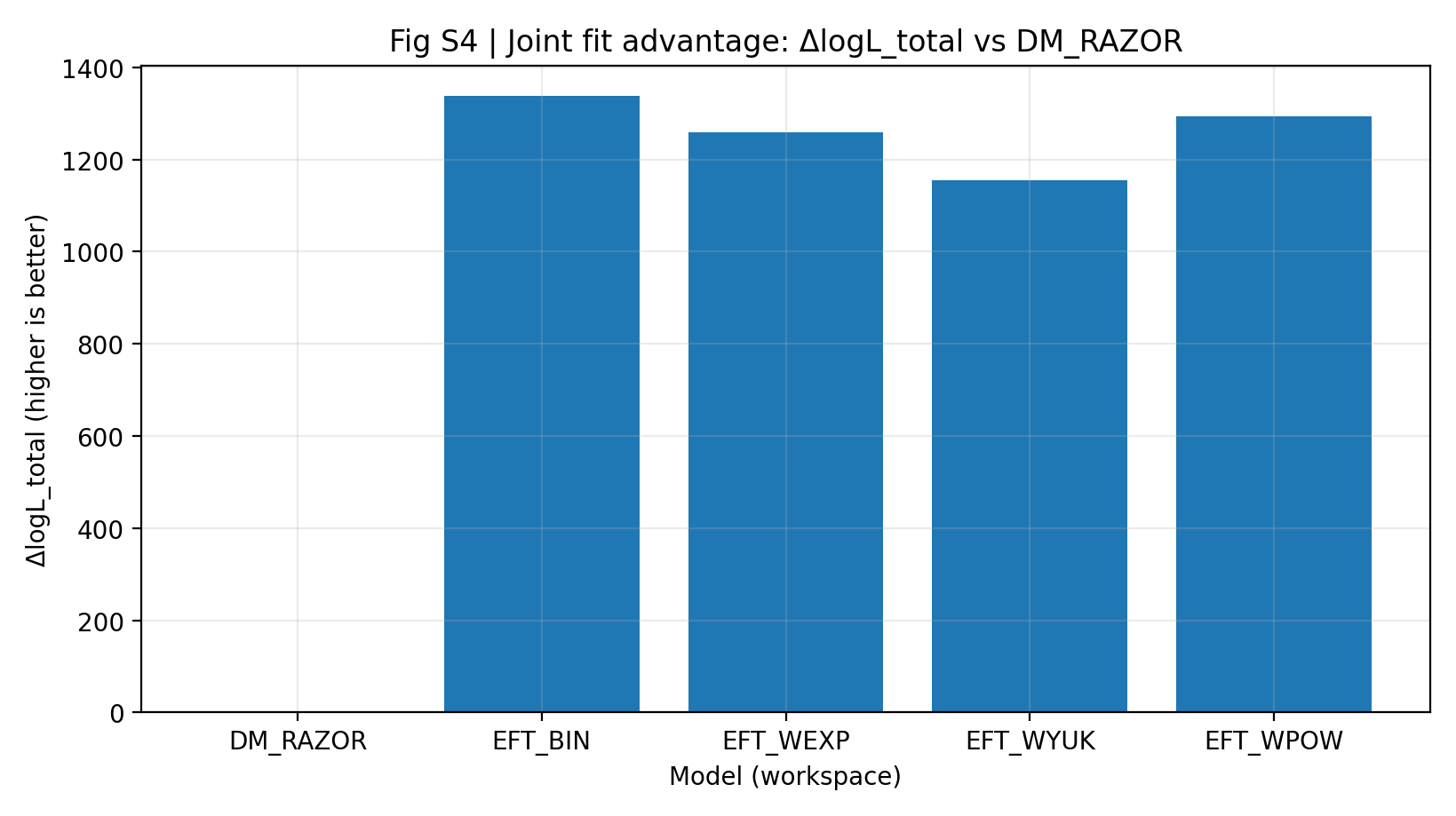
Rys. S4 | Przewaga dopasowania wspólnego (więcej znaczy lepiej): najlepsze logL_total dla RC+GGL względem DM_RAZOR.
2.4 Cztery wnioski (do bezpośredniego cytowania)
(1) W jednolitej analizie wspólnej krzywych rotacji SPARC i słabego soczewkowania KiDS-1000 model ram średniej grawitacji EFT systematycznie przewyższa DM_RAZOR w ścisłym protokole kontrolnym: ΔlogL_total = 1155–1337 względem DM_RAZOR.
(2) Test domknięcia RC→GGL wykazuje silniejszą spójność predykcyjną EFT: ΔlogL_closure = 172–281, wobec 127 dla DM_RAZOR. Gdy grupowanie RC-bin→GGL-bin zostaje losowo przetasowane, sygnał domknięcia spada do 6–23, co wskazuje, że zależy on od poprawnego odwzorowania między danymi, a nie od przypadkowego dopasowania.
(3) Systematyczne skany σ_int, R_min i kurczenia kowariancji nie zmieniają znaku ani skali wniosku „EFT przewyższa DM_RAZOR”, co wskazuje, że konkluzja jest odporna na typowe zaburzenia systematyczne.
(4) W tym samym protokole domknięcia Dodatek B (P1A) wzmacnia linię bazową DM w sposób „standaryzowany i audytowalny”: zachowuje trzy jednoparametrowe wzmocnienia (SCAT/AC/FB) oraz dodaje hierarchiczny rozrzut c–M + prior, jednoparametrowy proxy jądra i kalibrację ścinania po stronie soczewkowania m (wraz z ich modelem łączonym DM_STD). Wyniki pokazują, że tylko gałąź feedback/core przynosi niewielką poprawę netto siły domknięcia (122.21→129.45, ΔΔlogL_closure≈+7.25); pozostałe wzmocnienia wnoszą wkład nieistotny albo ujemny. Wniosek główny nie zależy więc od tego, że DM_RAZOR jest nadmiernie słabą linią bazową.
3 Dane i wstępne przetwarzanie
W badaniu wykorzystano dwa publiczne zbiory danych. W przepływie inżynieryjnym pobieranie, weryfikacja sum kontrolnych (sha256) i wstępne przetwarzanie są wykonywane przez skrypty możliwe do prześledzenia. Aby zapewnić uczciwe porównanie między modelami, wszystkie przestrzenie robocze (EFT_BIN / EFT_WEXP / EFT_WYUK / EFT_WPOW / DM_RAZOR) korzystają dokładnie z tych samych produktów danych i odwzorowań koszyków.
3.1 Krzywe rotacji (RC, SPARC)
Dane RC pochodzą z plików Rotmod_LTG bazy SPARC (175 plików rotmod). Po przetworzeniu próbka modelowania obejmuje 104 galaktyki i 2295 punktów danych (r, V_obs), podzielonych na 20 koszyków RC według masy gwiazdowej i kryteriów pokrewnych. Każdy punkt danych zawiera promień r (kpc), obserwowaną prędkość V_obs (km/s), błąd obserwacyjny σ_obs oraz prędkości składowych gazu/dysku/zgrubienia (V_gas, V_disk, V_bul).
3.2 Słabe soczewkowanie (GGL, KiDS-1000 / Brouwer+2021)
Dane GGL wykorzystują nadmiarową gęstość powierzchniową ΔΣ(R) z rys. 3 w pracy Brouwer et al. (2021), opartą na KiDS-1000 (4 koszyki masy gwiazdowej, 15 punktów R na koszyk), wraz z dostarczoną pełną kowariancją. W przepływie inżynieryjnym oryginalna kowariancja w formacie długim jest rekonstruowana do macierzy 15×15 dla każdego koszyka, a audyty Stage-B weryfikują rozsądność wymiarową i numeryczną.
3.3 Odwzorowanie RC-bin → GGL-bin i całkowity rozmiar próbki
4 koszyki masy GGL i 20 koszyków RC są połączone stałym odwzorowaniem: każdemu koszykowi GGL odpowiada 5 koszyków RC, a wkłady koszyków RC są ważone liczbą galaktyk. To odwzorowanie pozostaje stałe we wszystkich modelach i jest podstawowym ograniczeniem uczciwego porównania w testach domknięcia i dopasowaniu wspólnym. Końcowy wspólny zbiór danych zawiera n_total = 2355 punktów (RC=2295, GGL=60).
4 Modele i metody statystyczne
4.1 Minimalna specyfikacja matematyczna EFT i DM (audytowalna/testowalna)
Ta sekcja podaje minimalną specyfikację matematyczną, która bezpośrednio mapuje się na implementację.
(a) Model krzywej rotacji (RC)
Dla każdego punktu danych RC (r, V_obs, σ_obs) stosujemy superpozycję składowych: V_mod²(r) = V_bar²(r) + V_extra²(r). Tutaj V_bar²(r) = V_gas²(r) + Υ_d·V_disk²(r) + Υ_b·V_bul²(r). Główne wyniki w tej pracy przyjmują Υ_d = Υ_b = 0.5, zgodnie z empirycznymi zaleceniami SPARC i w celu ograniczenia niepotrzebnych stopni swobody.
(b) Korekta średniej grawitacji EFT (EFT)
Dodatkowy człon EFT jest parametryzowany w postaci „średniej prędkości do kwadratu”: V_extra²(r) = V0_bin² · f(r/ℓ). Tutaj V0_bin jest parametrem amplitudy dla każdego koszyka RC (20 parametrów), ℓ jest skalą globalną (1 parametr), a f(x) jest bezwymiarową funkcją kształtu jądra. Porównywane w tej pracy kształty jądra (żaden z nich nie wprowadza dodatkowych ciągłych stopni swobody) to:
- none: f(x)=x/(1+x)
- exponential: f(x)=1−exp(−x)
- yukawa: f(x)=1−exp(−x)·(1+0.5x)
- powerlaw_tail: f(x)=1−(1+x)^(−1/2)
- (kontrola opcjonalna) gaussian: f(x)=erf(x/√2) (nie uwzględniono w głównym zestawie wniosków)
Motywacja fizyczna (rozszerzona): EFT interpretuje dodatkową odpowiedź grawitacyjną w skalach galaktycznych jako odpowiedź efektywną uzyskaną przez gruboziarnienie/uśrednianie skalowe bardziej mikroskopowych działań na skończonych skalach. W tej pracy nie zakładamy konkretnego mechanizmu mikroskopowego; stosujemy minimalną i audytowalną parametryzację do kontrolowanego porównania i testowania w jednolitym protokole statystycznym.
Intuicyjnie dodatkowy człon można zapisać w postaci przyspieszenia: a_extra(r)=V_extra²(r)/r=(V0_bin²/r)·f(r/ℓ). Gdy r≫ℓ, f→1 i V_extra→V0_bin, dając w przybliżeniu płaski wkład dodatkowej prędkości w obszarze zewnętrznym. Gdy r≪ℓ i f(x)≈x, można wprowadzić charakterystyczną skalę przyspieszenia a0,bin≈V0_bin²/ℓ (z dokładnością do czynnika O(1) funkcji jądra), co daje MOND-podobną intuicję przejścia od obszaru wewnętrznego do zewnętrznego.
Dyskretna rodzina jąder użyta tutaj (none/exponential/yukawa/powerlaw_tail) może być traktowana jako niskowymiarowe proxy różnych „początkowych nachyleń / szybkości przejścia / długozasięgowych ogonów” (na przykład ekranowania typu Yukawy kontra odpowiedzi o dłuższym ogonie). Służą one testom odporności, a nie wyczerpaniu przestrzeni modeli. W komponencie słabego soczewkowania konstruujemy efektywną masę i gęstość otoczki z V_avg(r), a następnie rzutujemy je w celu uzyskania ΔΣ(R). Tę efektywną gęstość należy rozumieć jako opis efektywny potencjału soczewkującego przy założeniach symetrii sferycznej i mapowania słabego pola (pełne szczegóły przeniesiono do Dodatku A).
Wszystkie powyższe kształty jąder spełniają f(x)→1 dla x→∞ (tj. nasycenie V_extra²→V0²), dając jednocześnie liniowy lub podliniowy wzrost dla x≪1: na przykład exponential: f≈x; yukawa: f≈0.5x; powerlaw_tail: f≈0.5x. Różne kształty jądra mają więc obserwowalne różnice w małopromieniowym „początkowym nachyleniu”, szybkości przejścia i zewnętrznym ogonie, i mogą być rozróżniane przez wspólne testy RC+GGL oraz testy domknięcia.
Predykcja EFT dla słabosoczewkowego ΔΣ(R) jest uzyskiwana przez inferencję masy i gęstości otoczki z V_avg(r), po czym wykonuje się całki rzutowe: M_enc(r)=r·V_avg²(r)/G, ρ(r)=(1/4πr²)·dM_enc/dr, Σ(R)=2∫_R^∞ ρ(r)·r/√(r²−R²) dr oraz ΔΣ(R)=Σ̄(<R)−Σ(R). Implementacja numeryczna wykorzystuje siatkę logarytmiczną i w przypadkach wyjątkowych adaptacyjnie ją zagęszcza, aby zapewnić stabilność i reprodukowalność.
(c) DM_RAZOR: linia bazowa halo NFW zimnej ciemnej materii
Jednocześnie jasno stwierdzamy, że DM_RAZOR reprezentuje jedynie minimalną, audytowalną linię bazową NFW (stałe c–M i brak rozrzutu; brak kontrakcji adiabatycznej, jądra feedbacku, niesferyczności oraz członów środowiskowych). Aby zmniejszyć ryzyko „słomianej linii bazowej”, praca ta nie twierdzi, że takie efekty nie istnieją. Zamiast tego włącza je w Dodatku B (P1A) jako niskowymiarowe i audytowalne testy obciążeniowe, obejmujące hierarchiczne potraktowanie rozrzutu c–M, proxy jądra oraz zmienną nuisance kalibracji ścinania po stronie soczewkowania.
4.2 Księga modeli i uczciwe porównanie (wspólne parametry = definicja domknięcia)
Liczba parametrów w głównym zestawie porównawczym wynosi: DM_RAZOR k=20; rodzina EFT k=21 (dodatkowym parametrem jest globalny log ℓ). Wszystkie modele dzielą te same dane RC, te same dane GGL i kowariancję, to samo odwzorowanie RC-bin→GGL-bin, te same człony barionowe oraz te same konwersje jednostek. Ponadto kształt jądra (none / exponential / yukawa / powerlaw_tail) jest wyborem dyskretnym i nie wprowadza dodatkowego parametru ciągłego, co zapobiega uzyskaniu przewagi dzięki „jednemu dodatkowemu stopniowi swobody”.
4.3 Wiarygodność, priory i sampler
Wiarygodność RC jest diagonalnie gaussowska: σ_eff² = σ_obs² + σ_int². Główne wyniki ustalają σ_int=5 km/s, a Run-5 skanuje σ_int. Wiarygodność GGL używa pełnokowariancyjnej gaussowskiej postaci dla każdego koszyka: logL_GGL = Σ_b log 𝒩(ΔΣ_obs^b | ΔΣ_mod^b, C_b). Funkcja celu wspólnego to logpost(θ)=logprior(θ)+logL_RC(θ)+logL_GGL(θ). Priory kodują głównie fizycznie dopuszczalne granice (ograniczenia przedziałowe na log ℓ, log V0 i log M200); gdy włączone są swobodne Υ i σ_int, stosuje się słabo informatywne priory (szczegóły w implementacji i konfiguracji pakietu wydania).
Sampler wykorzystuje adaptacyjny blokowy losowy spacer Metropolisa: każdy krok aktualizuje tylko losowy podblok przestrzeni parametrów, aby poprawić współczynnik akceptacji w dużych wymiarach, a rozmiar kroku jest lekko dostrajany przez okienkowy współczynnik akceptacji (docelowo około 0.25). Główne wyniki używają trybu quick (np. n_steps=800), a każda przestrzeń robocza generuje ślady, reszty i wykresy PPC do audytu ręcznego i skryptowego.
4.4 Test domknięcia i kontrola negatywna (definicja)
Test domknięcia (Run-2) sprawdza, czy posterior z samego RC potrafi przewidzieć GGL bez ponownego dopasowania GGL. Konkretnie, z próbek posterior RC-only generuje się w przód ΔΣ(R) dla 4 koszyków GGL i oblicza logL_true z pełną kowariancją; następnie losowo permutuje się odwzorowanie grup RC-bin→GGL-bin, aby uzyskać logL_perm. Siła domknięcia jest zdefiniowana jako ΔlogL_closure≡⟨logL_true⟩−⟨logL_perm⟩. Dodatkowo Run-10 losowo przegrupowuje 20 koszyków RC w 4×5 (shuffle) i ponownie oblicza domknięcie, testując, jak silnie sygnał domknięcia zależy od poprawnego odwzorowania.
5 Główne wyniki i interpretacja
5.1 Główne wyniki dopasowania wspólnego (RC+GGL)
Najlepsze logL_total z dopasowania wspólnego oraz względna przewaga ΔlogL_total (względem DM_RAZOR) są pokazane w tabeli S1a i na rys. S4. W głównym zestawie porównawczym EFT_BIN ma największą przewagę wspólną (ΔlogL_total=1337.210), a pozostałe kształty jąder EFT również zachowują znaczące przewagi (1154.827–1294.442). Według kryteriów informacyjnych (AICc/BIC) rodzina EFT także wyraźnie przewyższa DM_RAZOR, co wskazuje, że przewaga nie wynika z błędu związanego z liczbą parametrów.
Uwaga: główny wkład do ΔlogL_total≈1337 pochodzi z członu RC (ΔlogL_RC≈1065 w dekompozycji wspólnej, około 80%). Można to rozumieć jako umiarkowaną poprawę rzędu Δχ²≈0.90 na punkt w N=2295 punktach danych RC, która naturalnie kumuluje się do przewagi rzędu 10^3 przy diagonalnej wiarygodności gaussowskiej. Jednocześnie GGL i test domknięcia dostarczają niezależnych ograniczeń między zbiorami danych, a ranking pozostaje stabilny w testach obciążeniowych σ_int, R_min i cov-shrink (zob. sekcja 6 i tabela S1b).
5.2 Wyniki testu domknięcia (RC-only → GGL)
Kluczowa wielkość testu domknięcia ΔlogL_closure jest raportowana w tabeli S1b i na rys. S3. Rodzina EFT ma siły domknięcia 171.977–280.513, wyższe niż 126.678 dla DM_RAZOR. Oznacza to, że bez dopuszczania dodatkowych stopni swobody między danymi próbki posterior uzyskane przez EFT z danych RC mają silniejszą przenoszalną moc predykcyjną dla danych GGL.
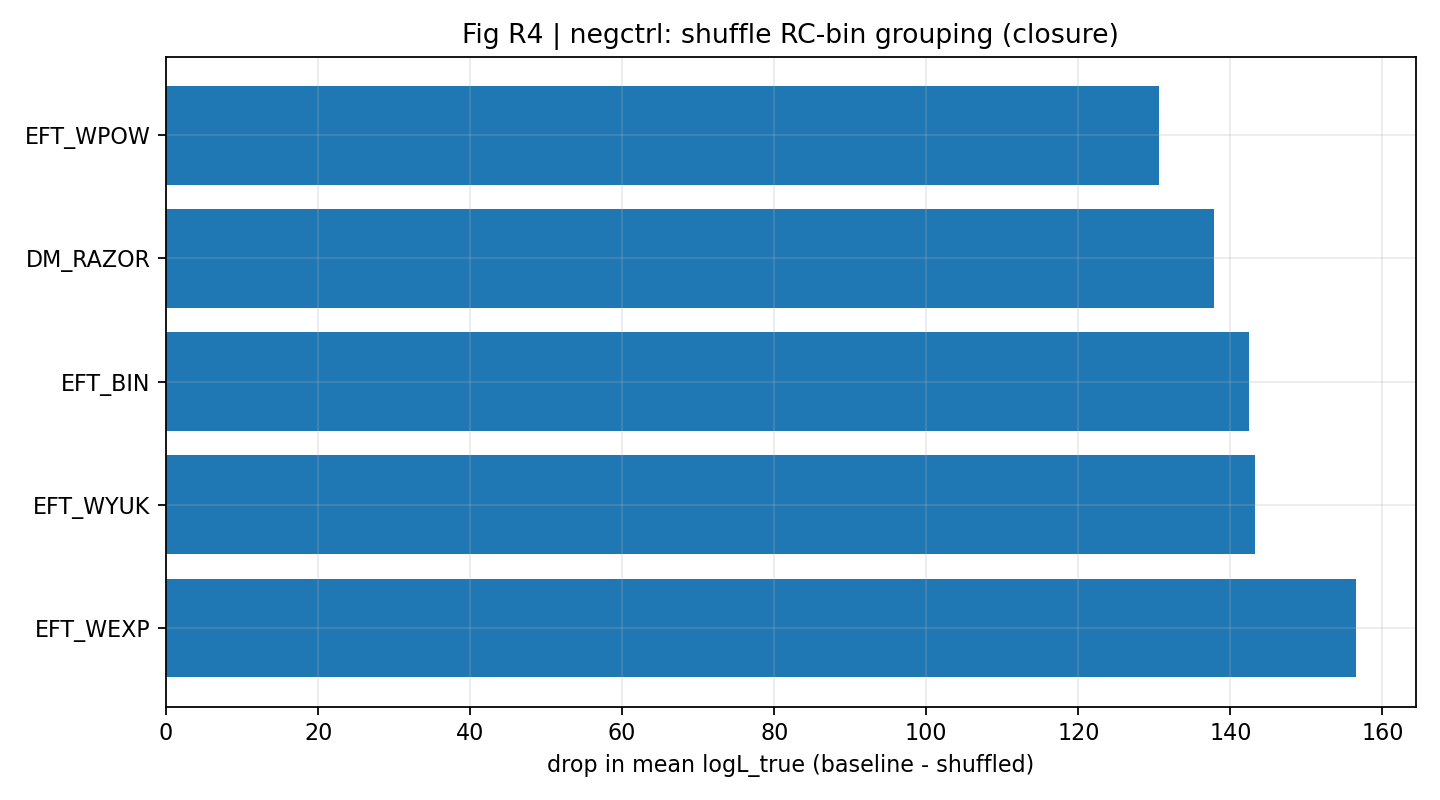
Kontrola negatywna dodatkowo wspiera fizyczne znaczenie sygnału domknięcia: gdy grupowanie RC-bin→GGL-bin jest losowo przetasowane, siła domknięcia EFT spada do 6–15 (z niewielkimi różnicami między jądrami), podczas gdy bazowa siła domknięcia wynosi 172–281. To „załamanie sygnału” wyklucza fałszywe przewagi spowodowane implementacją numeryczną, błędami jednostek lub niewłaściwą obsługą kowariancji.
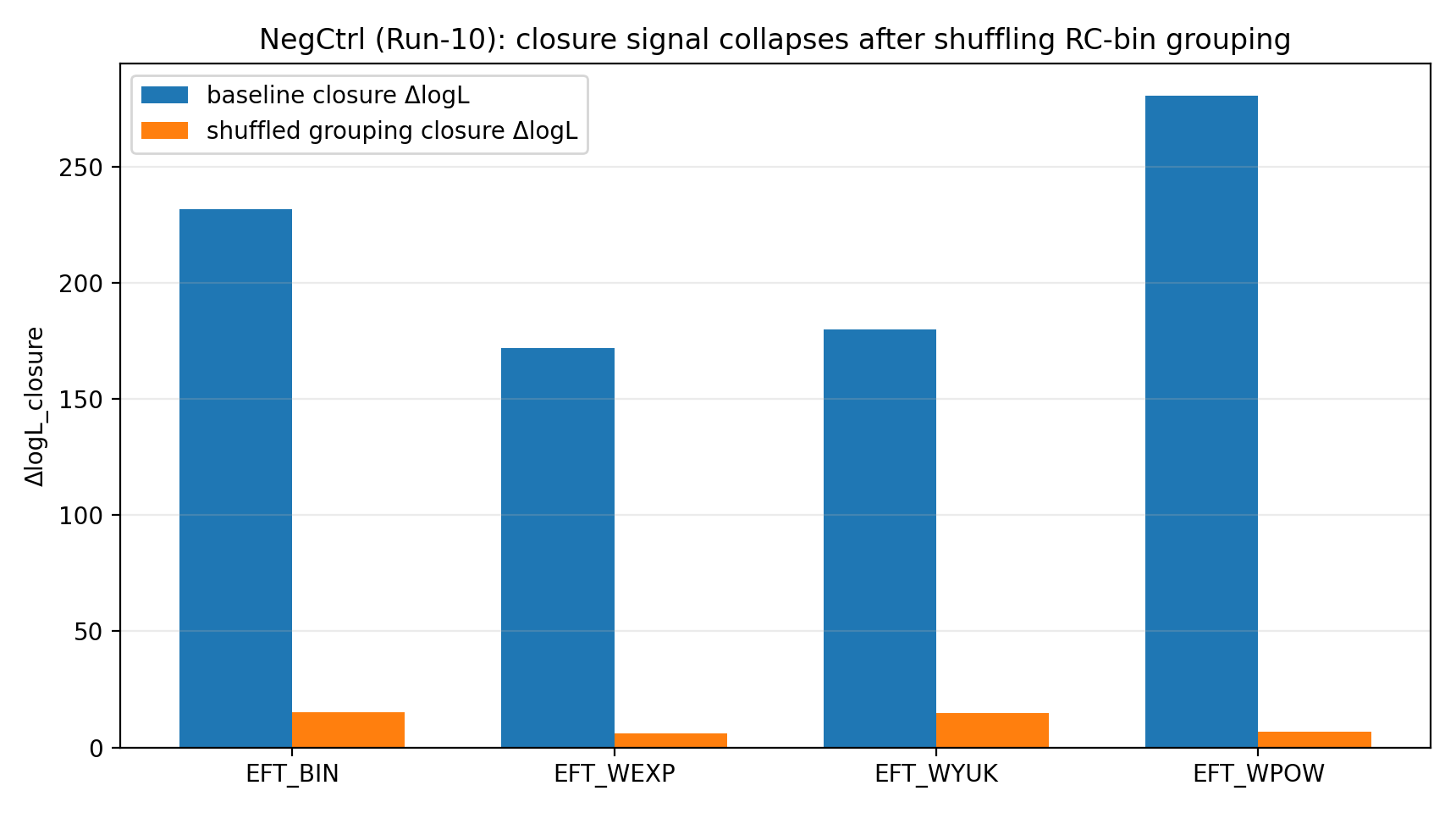
Rys. R1 | Kontrola negatywna: po przetasowaniu grupowania sygnał domknięcia wyraźnie spada (wykreślono z metryk Tab_Z1).
5.3 Znaczenie i granice wyników
Wniosek tego badania brzmi: „przy tym zbiorze danych i tym protokole korekta średniej grawitacji EFT przewyższa testowaną linię bazową DM_RAZOR”. Trzeba podkreślić, że strona DM używa jedynie minimalnej linii bazowej NFW ze stałą relacją c(M), bez formowania jądra, niesferyczności, członów środowiskowych ani bardziej złożonych modeli połączenia galaktyka–halo. Manuskrypt nie twierdzi więc, że wyklucza wszystkie rodziny modeli DM. Zamiast tego dostarcza reprodukowalną, zorientowaną na test domknięcia linię bazową kontroli do oceny, czy RC i GGL mogą być spójnie wyjaśnione przez te same parametry i odwzorowanie między danymi.
Aby odpowiedzieć na tę częstą wątpliwość, ukończyliśmy niezależny projekt rozszerzający, P1A (zob. Dodatek B). Bez zmiany wspólnego odwzorowania RC-bin→GGL-bin ani ram audytu wzmacnia on linię bazową DM w sposób „standaryzowany i audytowalny”: poza trzema jednoparametrowymi wzmocnieniami (SCAT/AC/FB) dodaje (i) hierarchiczny rozrzut c–M + prior masa–koncentracja (DM_HIER_CMSCAT), (ii) jednoparametrowy proxy jądra feedbacku barionowego (DM_CORE1P) oraz (iii) nuisance kalibracji ścinania po stronie słabego soczewkowania m (DM_RAZOR_M), a także raportuje model łączony DM_STD; EFT_BIN pozostaje referencją kontrolną.
• DM_RAZOR_SCAT (rozrzut c–M) — wprowadza parametr rozrzutu koncentracji między halo σ_logc, aby sprawdzić, czy stałe c(M) systematycznie nie zaniża mocy wyjaśniającej DM;
• DM_RAZOR_AC (kontrakcja adiabatyczna) — używa pojedynczego parametru α_AC, aby płynnie interpolować między „brakiem kontrakcji” a „standardową kontrakcją”, ujmując minimalnym kosztem tendencję barionów do kurczenia wewnętrznego halo;
• DM_RAZOR_FB (feedback/jądro) — używa skali jądra (np. log r_core), aby opisać, jak formowanie wewnętrznego jądra tłumi krzywe rotacji, zachowując przybliżenie NFW w skalach słabego soczewkowania.
Ilościowa tablica wyników P1A znajduje się w Dodatku B, tabela B1 / rys. B1 (automatycznie wygenerowana z Tab_S1_P1A_scoreboard). W metryce domknięcia DM_RAZOR_FB daje niewielką poprawę netto (122.21→129.45, +7.25), podczas gdy pozostałe wzmocnienia wnoszą wkład nieistotny lub ujemny. Po stronie dopasowania wspólnego dodanie hierarchicznego prioru rozrzutu c–M (DM_HIER_CMSCAT) albo modelu łączonego (DM_STD) może znacznie poprawić wspólne logL, ale nie poprawia siły domknięcia, co sugeruje, że dodaje głównie elastyczności dopasowania wspólnego, a nie przenoszalności między sondami. Główny wniosek tekstu należy więc czytać następująco: przy ścisłych ograniczeniach wspólnego odwzorowania i testu domknięcia przewaga spójności między danymi EFT nie wynika z wyboru „nadmiernie słabej linii bazowej” po stronie DM. Pakiet wydania P1A odpowiadający Dodatkowi B (dodatkowe tabele/rysunki oraz full_fit_runpack) zostanie dołączony jako dodatkowe pliki pod tym samym Zenodo Concept DOI co full_fit_runpack dla tej pracy: https://doi.org/10.5281/zenodo.18526286.
6 Odporność i eksperymenty kontrolne
6.1 Skan σ_int (Run-5)
Systematycznie skanujemy wewnętrzny rozrzut RC σ_int i powtarzamy wspólną inferencję dla każdej wartości σ_int, obliczając ΔlogL_total względem DM_RAZOR. Minimalne/maksymalne wartości ΔlogL_total dla każdego modelu w zakresie skanu podano w tabeli S1b.
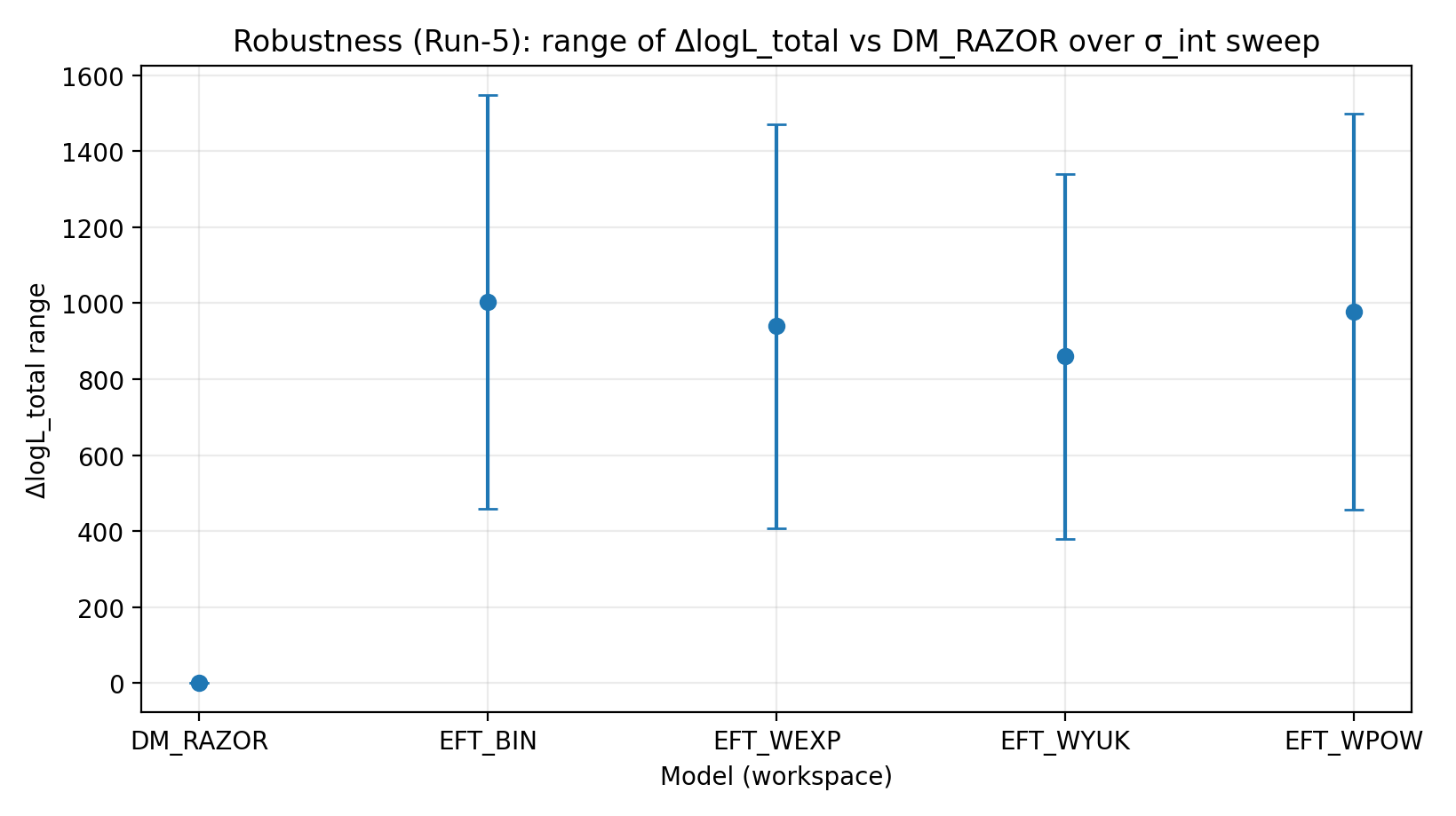
Rys. R2 | Zakres ΔlogL_total w skanie σ_int (więcej znaczy lepiej).
6.2 Skan R_min (Run-6)
Aby przetestować wpływ systematyk w danych obszaru centralnego (takich jak ruch niekołowy, rozdzielczość i niewystarczające modelowanie barionowe), nakładamy progi odcięcia R_min na RC i powtarzamy inferencję wspólną. W skanie R_min przewaga rodziny EFT pozostaje dodatnia i stabilna co do skali.
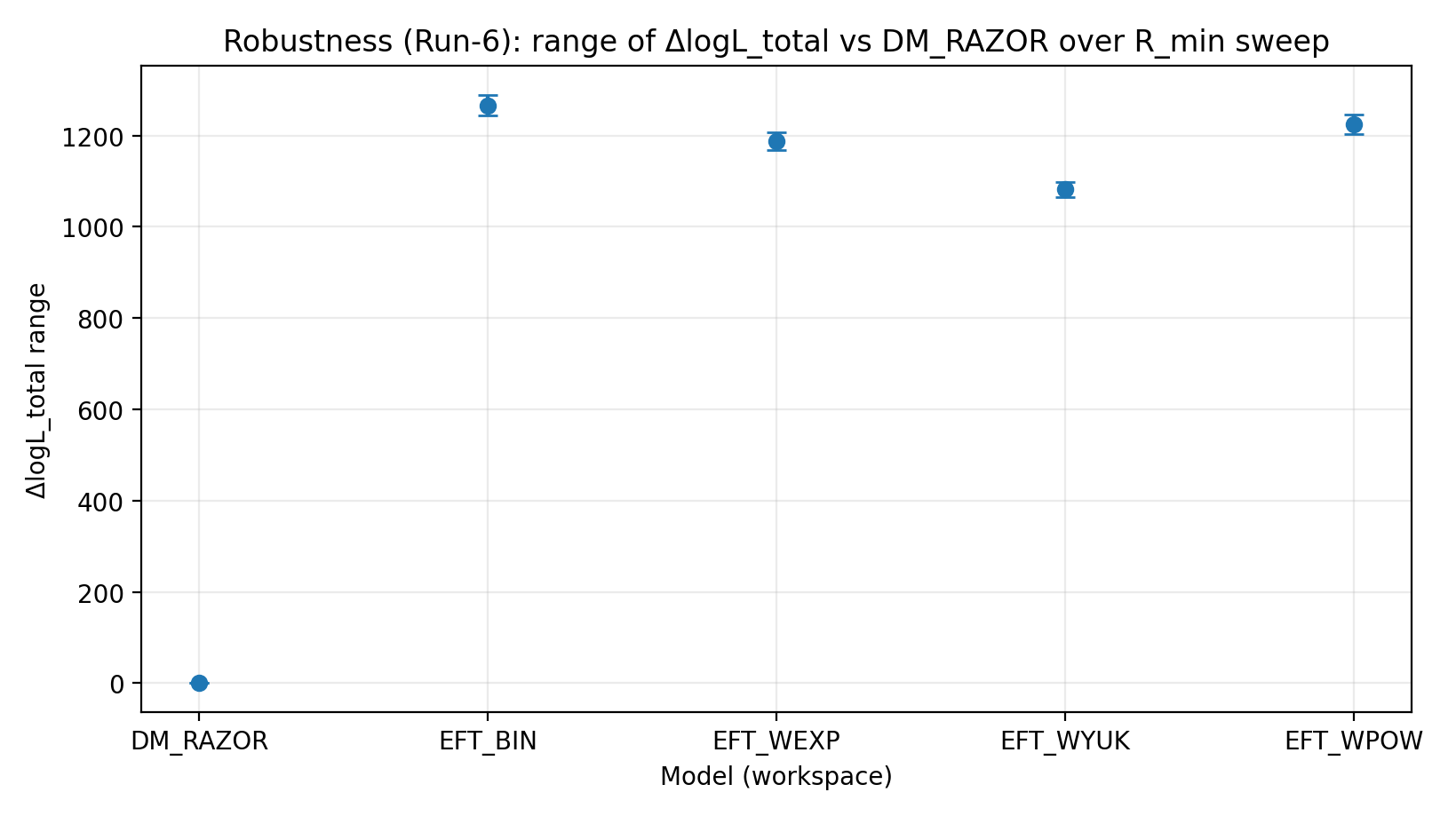
Rys. R3 | Zakres ΔlogL_total w skanie R_min (więcej znaczy lepiej).
6.3 Skan cov-shrink (Run-7)
Aby przetestować niepewność kowariancji GGL, stosujemy shrinkage do macierzy kowariancji każdego koszyka masy: C_α=(1−α)C+α·diag(C), i skanujemy α. Wyniki pokazują, że przewaga rodziny EFT jest niewrażliwa na ten zabieg.
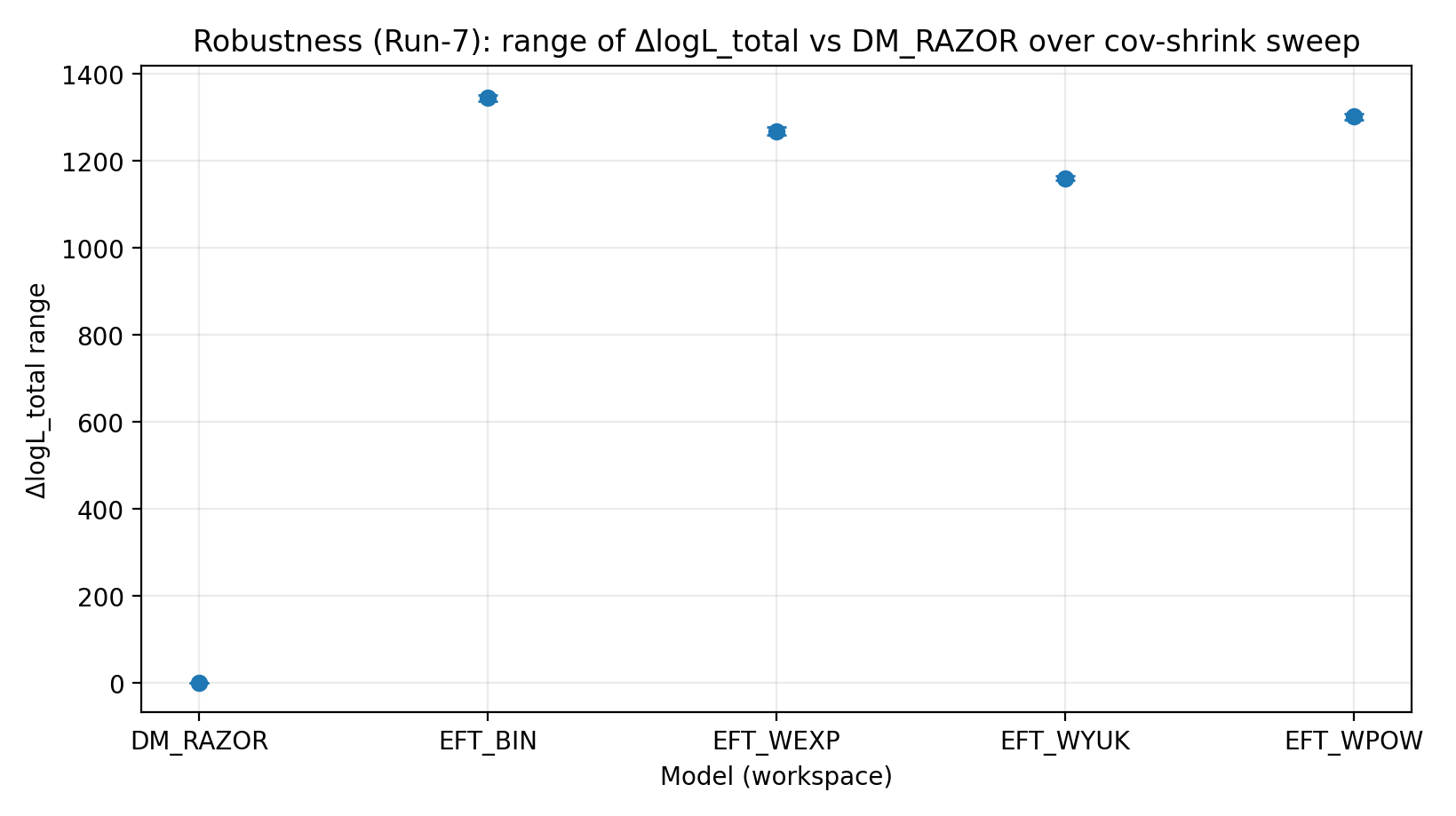
Rys. R4 | Zakres ΔlogL_total w skanie cov-shrink (więcej znaczy lepiej).
6.4 Drabina ablacji (Run-8)
W ramach EFT_BIN wykonujemy zagnieżdżone ablacje: od modelu minimalnego (bez parametrów swobodnych), przez wersje zachowujące jedynie małą liczbę stopni swobody, aż po kompletny model z amplitudą 20 koszyków + globalną skalą. AICc/BIC pokazują, że kompletny model EFT_BIN jest silnie wymagany przez dane.
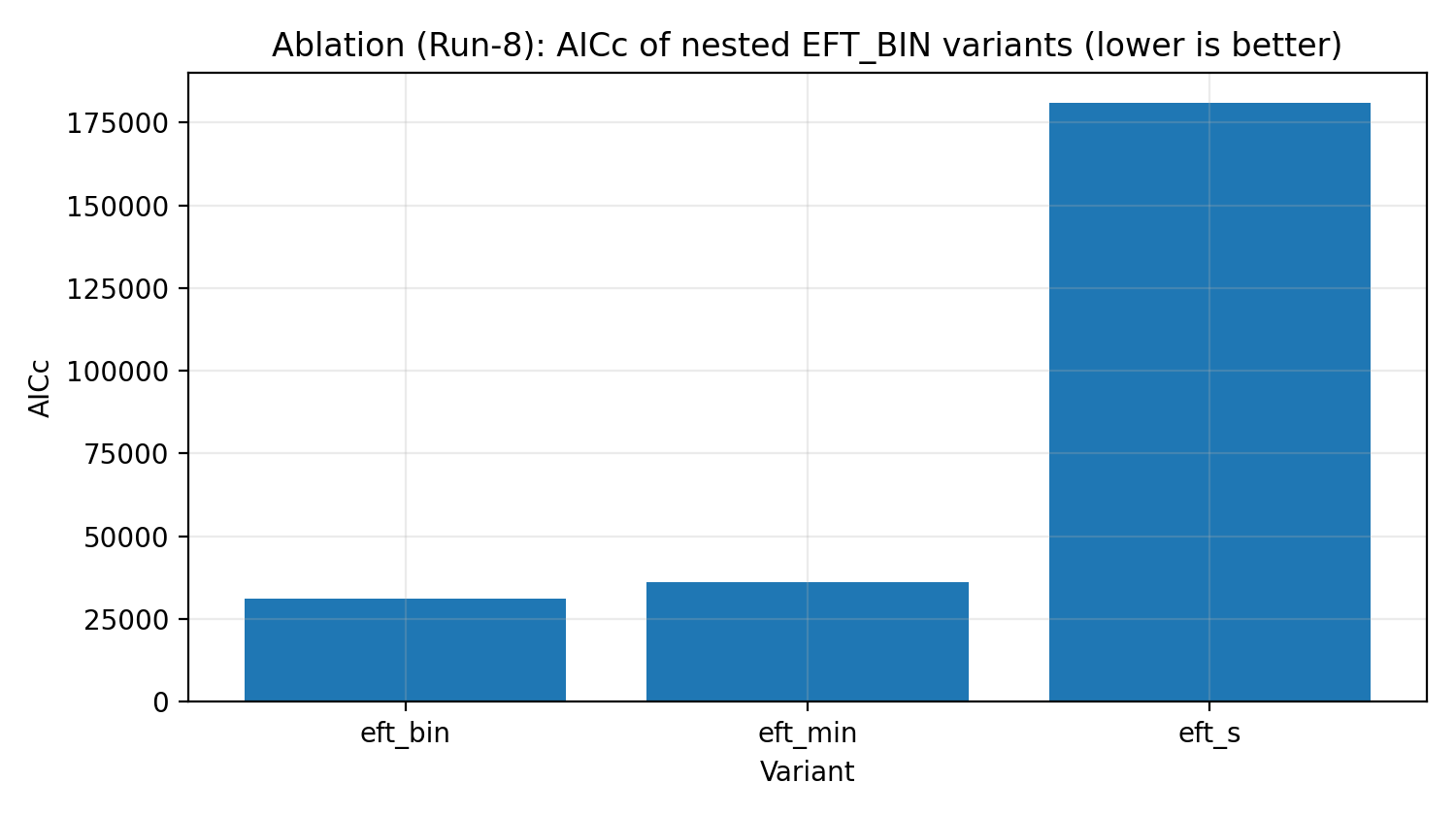
Rys. R5 | Drabina ablacji EFT_BIN (AICc; mniej znaczy lepiej).
6.5 Predykcja holdout (Run-9)
Dodatkowo wykonujemy test leave-one-bin-out (LOO): spośród 4 koszyków masy GGL za każdym razem jeden koszyk jest wstrzymywany; inferencję powtarza się na pozostałych koszykach (i wszystkich RC), a log-wiarygodność testową ocenia się następnie na koszyku wstrzymanym. Metryki zbiorcze podano w tabeli uzupełniającej Tab_R3_leave_one_bin_out (produkt Run-9; wzorce ścieżek plików wymieniono w liście kluczowych produktów w sekcji 8.2). Rodzina EFT pozostaje wyraźnie lepsza od DM_RAZOR nawet w najgorszym przypadku wstrzymanego koszyka.
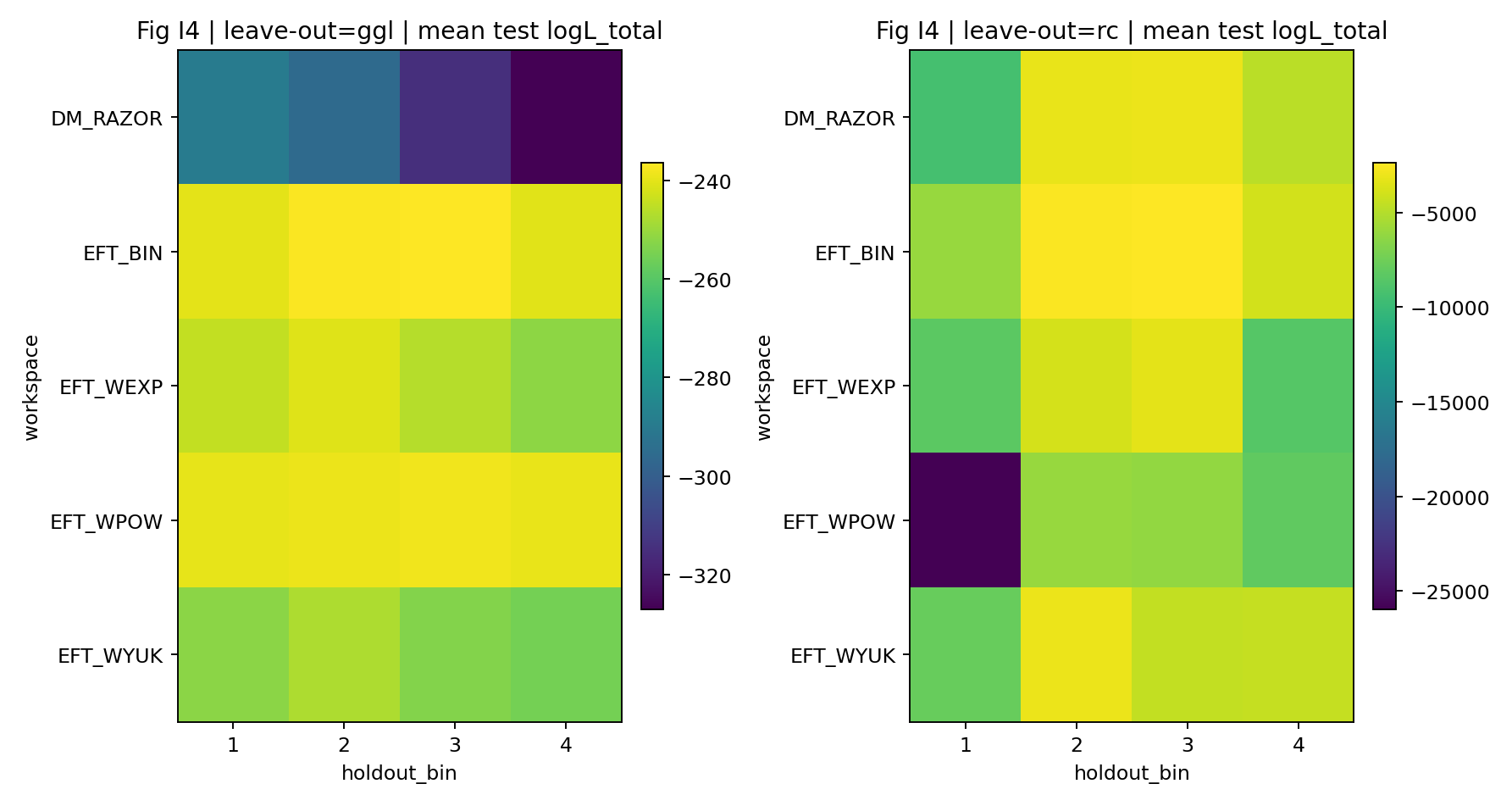
Rys. R6 | LOO: rozkład log-wiarygodności dla koszyka wstrzymanego (z produktów Run-9).
6.6 Kontrola negatywna: przetasowanie koszyków RC (Run-10)
Run-10 losowo przegrupowuje 20 koszyków RC w 4×5 i ponownie oblicza domknięcie, zachowując posterior RC-only bez zmian. Wyniki pokazują, że w porównaniu z oryginalnym odwzorowaniem przetasowanie znacząco obniża zarówno średnie logL_true domknięcia, jak i ΔlogL_closure (zob. tabela S1b i rys. R1), co dodatkowo wspiera interpretowalność sygnału domknięcia.
Rys. R7 | Kontrola negatywna: odwzorowanie shuffle powoduje wyraźny spadek średniego logL_true domknięcia (z produktów Run-10).
7 Identyfikowalność i audyt spójności (pochodzenie)
Wszystkie wartości liczbowe cytowane w tej pracy można prześledzić pozycja po pozycji w ścisłych tabelach zbiorczych i zapisach audytowych archiwum wydania. Aby tekst główny był czytelniejszy, pełny łańcuch pochodzenia (lista tagów, tabele audytu, lista sum kontrolnych i metoda weryfikacji) przeniesiono do Dodatku A.
8 Reprodukowalność i archiwum Zenodo
Deklaracja dostępności danych i kodu: dane krzywych rotacji SPARC oraz dane słabego soczewkowania KiDS-1000 użyte w tej pracy są zbiorami publicznymi. Raport w wersji publikacyjnej zarchiwizowano w Zenodo (Concept DOI: https://doi.org/10.5281/zenodo.18526334), a pełny pakiet reprodukcyjny zarchiwizowano w Zenodo (Concept DOI: https://doi.org/10.5281/zenodo.18526286). Szczegółowe kroki wykonania, środowisko zależności, inwentarz archiwum i informacje o weryfikacji hash podano w Dodatku A; projekt, tagi uruchomień i wyniki testu standaryzacji linii bazowej DM (P1A) podano w Dodatku B.
Pod tym samym Concept DOI pełnego pakietu reprodukcyjnego (https://doi.org/10.5281/zenodo.18526286) udostępniamy dwa reprodukowalne punkty wejścia według zastosowania: • full_fit_runpack P1 (tekst główny): odtwarza analizy RC-only / closure / joint oraz skany odporności dla EFT vs DM_RAZOR i generuje zasoby tekstu głównego, w tym tabele S1a/S1b oraz rys. S3/S4; • full_fit_runpack P1A (Dodatek B): odtwarza test standaryzacji linii bazowej DM (SCAT/AC/FB + hierarchiczny prior rozrzutu c–M + core1p + lensing m + DM_STD, w tym kontrolę EFT_BIN) oraz generuje tabelę B1 i rys. B1 Dodatku. Dodatkowe tabele/rysunki P1A oraz full_fit_runpack zostaną dołączone jako dodatkowe pliki pod tym samym Concept DOI, aby utrzymać pojedynczy punkt wejścia do archiwum.
9 Podziękowania i deklaracje
9.1 Podziękowania
Dziękujemy zespołom SPARC i KiDS-1000 za udostępnienie publicznych danych i dokumentacji oraz uczestnikom przepływu rekonstrukcji i audytu w tym projekcie.
9.2 Wkład autora
Guanglin Tu odpowiadał za propozycję koncepcyjną, projekt badania, implementację inżynieryjną, kurację danych, analizę formalną, implementację i audyt przepływu reprodukcyjnego oraz napisanie manuskryptu.
9.3 Finansowanie
Praca finansowana samodzielnie przez autora, Guanglina Tu (brak finansowania zewnętrznego / brak numeru grantu).
9.4 Konflikt interesów
Autor, Guanglin Tu, jest związany z „EFT Working Group, Shenzhen Energy Filament Science Research Co., Ltd. (Chiny)”; nie zadeklarowano żadnych innych konfliktów interesów.
9.5 Wsparcie AI
OpenAI GPT-5.2 Pro i Gemini 3 Pro wykorzystano do korekty językowej, redakcji strukturalnej i organizacji przepływu reprodukcyjnego. Nie użyto ich do generowania ani modyfikowania danych, wyników, rysunków, tabel ani kodu, ani do generowania cytowań. Autor ponosi pełną odpowiedzialność za treść i poprawność cytowań całego manuskryptu.
10 Literatura
- Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
- Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
- Wright, C. O., & Brainerd, T. G. (2000). Gravitational Lensing by Navarro–Frenk–White Halos. The Astrophysical Journal, 534, 34–40.
- Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493. DOI: https://doi.org/10.1086/304888
- Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374. DOI: https://doi.org/10.1093/mnras/stu742
- Blumenthal, G. R., Faber, S. M., Flores, R., & Primack, J. R. (1986). Contraction of dark matter galactic halos due to baryonic infall. Astrophysical Journal, 301, 27. DOI: https://doi.org/10.1086/163867
- Di Cintio, A., Brook, C. B., Dutton, A. A., et al. (2014). A mass-dependent density profile for dark matter haloes including the influence of galaxy formation. Monthly Notices of the Royal Astronomical Society, 441, 2986–2995. DOI: https://doi.org/10.1093/mnras/stu729
- Read, J. I., Agertz, O., & Collins, M. L. M. (2016). Dark matter cores all the way down. Monthly Notices of the Royal Astronomical Society, 459, 2573–2590. DOI: https://doi.org/10.1093/mnras/stw713
- Teoria Włókna Energii. Zenodo (otwarte repozytorium naukowe) DOI: https://doi.org/10.5281/zenodo.18517411
Dodatek A: szczegóły identyfikowalności i reprodukowalności
Ten dodatek podsumowuje długoterminowe informacje archiwalne dotyczące identyfikowalności i reprodukowalności, w tym tagi uruchomień, wyniki audytów, inwentarze archiwalne i kluczowe punkty weryfikacji, tak aby czytelnicy mogli w razie potrzeby sprawdzić i odtworzyć pracę.
A.1 Szczegóły identyfikowalności i audytu
Aby zapewnić długoterminową identyfikowalność, projekt używa tagów czasowych dla każdego uruchomienia i produktu oraz zachowuje produkty historyczne bez ich nadpisywania. Wartości rdzeniowe cytowane w manuskrypcie pochodzą ze ścisłej kompilacji (compile_tag=20260205_035929) i przeszły następujące audyty spójności:
• Wszystkie tabele na poziomie etapów zawierają run_tag i tagi etapów; skrypt ścisłej kompilacji wybiera z report/tables „kompletne i spójne” kanoniczne źródła tabel.
• Wartości w Tab_Z1_master_summary i Tab_Z2_conclusion_highlights są porównywane pozycja po pozycji z wybranymi tabelami kanonicznymi.
• Podczas generowania PDF wykonywany jest audyt tagów dla „tagów przywoływanych tabel/rysunków”, aby zapewnić, że nie mieszają się produkty nieaktualne.
Kluczowe tagi (do lokalizowania wszystkich produktów pośrednich): run_tag=20260204_122515; closure_tag=20260204_124721; joint_tag=20260204_152714; sigma_sweep_tag=20260204_161852; rmin_sweep_tag=20260204_195247; covshrink_tag=20260204_203219; ablation_tag=20260204_214642; LOO_tag=20260204_224827; negctrl_tag=20260204_234528; strict_compile_tag=20260205_035929; release_tag=20260205_112442.
Wynik audytu spójności: Tab_AUDIT_checks_strict raportuje pass=9, fail=0, skip=0 (szczegóły w pakiecie wydania).
A.2 Kroki wykonania reprodukcji i inwentarz archiwum
Badanie przyjmuje system reprodukowalności składający się z „raportu w wersji publikacyjnej + suplementu tabel/rysunków + w pełni ponownie uruchamialnego pakietu run”. Czytelnicy mogą bezpośrednio sprawdzić Tables & Figures Supplement, aby zweryfikować wszystkie zasoby tabel/rysunków cytowane w artykule; aby odtworzyć wartości liczbowe i łańcuch audytu od zera, mogą użyć full_fit_runpack do pobrania danych i ponownego uruchomienia pełnego przepływu. Po zakończeniu można użyć wbudowanego w pakiet skryptu porównania tabel referencyjnych, aby zweryfikować spójność wartości tabel.
A.2.1 Szybki start reprodukcji (RUN_FULL, Windows PowerShell)
Ta sekcja podaje krótszą ścieżkę reprodukcji (Windows PowerShell). Do szybkich kontroli zaleca się bezpośrednie sprawdzenie Tables & Figures Supplement i weryfikację cytowanych tabel oraz rysunków pozycja po pozycji. Do reprodukcji end-to-end i wygenerowania wszystkich tabel, rysunków i produktów audytu należy użyć full_fit_runpack: zgodnie z README/ONE_PAGE_REPRO_CHECKLIST pakietu uruchomić verify_checksums.ps1 i RUN_FULL.ps1 (zalecany Mode=full).
Wejście do archiwum Zenodo (Concept DOI): https://doi.org/10.5281/zenodo.18526286.
Tagi głównego łańcucha dla tej pracy: run_tag=20260204_122515; strict compile_tag=20260205_035929; release_tag=20260205_112442.
A.2.2 Materiały archiwalne i kluczowe punkty weryfikacji (pakiety i kontrole)
Archiwum Zenodo udostępnia trzy komplementarne kategorie materiałów: (1) raport w wersji publikacyjnej (niniejsza praca, v1.1; w tym Dodatek B: test standaryzacji linii bazowej DM P1A); (2) Tables & Figures Supplement (uzupełniające tabele i rysunki obejmujące wszystkie zasoby tabel/rysunków cytowane w tej pracy, osobno odpowiadające P1 i P1A); oraz (3) full_fit_runpack (pełny pakiet reprodukcyjny: pobiera dane od zera i ponownie uruchamia kompletny przepływ, osobno dla P1 i P1A). Pozycje (1)–(2) wspierają szybkie czytanie i niezależną weryfikację; pozycja (3) zapewnia pełną reprodukowalność end-to-end.
Kategoria materiału | Nazwa pliku (przykład) | Cel i pozycjonowanie (zalecana kolejność użycia) |
Raport w wersji publikacyjnej (chiński i angielski) | P1_RC_GGL_report_EN_PUBLICATION_V1_1.pdf | Pełny raport zarchiwizowany w Zenodo; tekst główny podaje zasadnicze wnioski i audyty odporności, a Dodatek B przedstawia P1A (test standaryzacji linii bazowej DM). |
Suplement tabel i rysunków (P1) | P1_RC_GGL_supplement_figs_tables_V1_1.zip | Wszystkie tabele (CSV) i rysunki (PNG) cytowane w tekście głównym, wraz ze skryptami generującymi i plikami tagów. |
Suplement tabel i rysunków (P1A) | P1A_supplement_figs_tables_v1.zip | Wszystkie tabele i rysunki cytowane w Dodatku B (P1A), w tym Tab_S1_P1A_scoreboard i Fig_S1_P1A_scoreboard. |
full_fit_runpack (P1) | P1_RC_GGL_full_fit_runpack_v1_1.zip | Pełna reprodukcja end-to-end: pobranie danych od zera i ponowne uruchomienie RC-only/closure/joint oraz skanów odporności. |
full_fit_runpack (P1A) | P1A_RC_GGL_full_fit_runpack_v1.zip | Pełna reprodukcja end-to-end (Dodatek B): ponowne uruchomienie DM 7+1 + DM_STD (w tym kontroli EFT_BIN) i wygenerowanie zasobów dodatku; pakiet zawiera skrypt porównania tabel referencyjnych do weryfikacji spójności wartości tabel. |
Zalecenie cytowania: cytując tę pracę lub towarzyszące jej materiały reprodukcyjne, prosimy cytować Zenodo Concept DOI (https://doi.org/10.5281/zenodo.18526334).
Kluczowe produkty, które powinny pojawić się po reprodukcji i nadawać się do porównania, obejmują:
- report/tables/Tab_D_closure_summary__20260204_122515__*.csv (podsumowanie domknięcia)
- report/tables/Tab_F_joint_summary__20260204_122515__*.csv (podsumowanie dopasowania wspólnego)
- report/tables/Tab_G_joint_sigma_sweep__20260204_122515__*.csv (skan σ_int)
- report/tables/Tab_H_joint_rmin_sweep__20260204_122515__*.csv (skan R_min)
- report/tables/Tab_I_joint_covshrink_sweep__20260204_122515__*.csv (skan cov-shrink)
- report/tables/Tab_R2_ablation_ladder__20260204_122515__*.csv (ablacja)
- report/tables/Tab_R3_leave_one_bin_out__20260204_122515__*.csv (LOO)
- report/tables/Tab_R4_negctrl_rcbin_shuffle__20260204_122515__*.csv (kontrola negatywna)
- report/final/Tab_Z1_master_summary__20260204_122515__20260205_035929.csv (ścisła tabela główna; odpowiada tabelom S1a/S1b i wartościom w tekście głównym)
- report/final/P1_RC_GGL_final_bundle__20260204_122515__20260205_035929.pdf (publikacyjny pakiet PDF; może służyć do szybkiego przeglądu i cytowania)
Dodatek B: P1A — test standaryzacji linii bazowej DM (DM 7+1 + DM_STD; z kontrolą EFT)
Ten dodatek dokumentuje projekt rozszerzający (P1A) dotyczący „testów obciążeniowych standaryzacji linii bazowej DM”, zgodny z protokołem domknięcia w tekście głównym. Jego rolą jest podniesienie minimalnej linii bazowej DM_RAZOR użytej w tekście głównym (NFW + stałe c–M, bez rozrzutu / bez kontrakcji / bez jądra) do zestawu linii bazowych DM bliższego praktyce astrofizycznej i odporniejszego na częste krytyki, bez wprowadzania dużej liczby stopni swobody i bez zmiany wspólnego odwzorowania RC-bin→GGL-bin ani ram audytu. P1A obejmuje wcześniejszy trójgałęziowy test obciążeniowy i jest jego nadzbiorem: zachowuje SCAT/AC/FB, dodając hierarchiczny rozrzut c–M + prior, jednoparametrowy proxy jądra oraz nuisance kalibracji ścinania po stronie soczewkowania m; udostępnia też model łączony DM_STD. EFT_BIN pozostaje referencją kontrolną.
Uwaga uzupełniająca: siły domknięcia i wartości pokrewne w Dodatku B (P1A) używają większego budżetu Monte Carlo (np. ndraw=400, nperm=24) niż szybki budżet zastosowany w tekście głównym do pokrycia pełnej rodziny jąder EFT (np. ndraw=60, nperm=12). Wartości bezwzględne mogą więc wykazywać dryf próbkowania rzędu O(10). Porównania model–model w obrębie tego samego budżetu/tabeli są jednak uczciwe, a znak i skala przewagi pozostają stabilne między budżetami.
B.1 Cel i pozycjonowanie (dlaczego P1A i dlaczego jako dodatek)
P1A nie próbuje wyczerpać wszystkich możliwych wyborów modelowania halo ΛCDM (takich jak niesferyczność, zależność środowiskowa, złożone połączenia galaktyka–halo czy wysokowymiarowa fizyka barionów). Zamiast tego P1A kieruje się zasadą „niskowymiarowości, audytowalności i reprodukowalności”: każdy moduł wzmocnienia wprowadza tylko ≤1 kluczowy parametr efektywny i pozostaje pod trzema twardymi ograniczeniami tej pracy:
(i) Księga parametrów: każdy nowy parametr musi być wyraźnie zapisany i raportowany razem z kryteriami informacyjnymi (AICc/BIC);
(ii) Wspólne odwzorowanie: nadal używana jest ta sama mapa grupowania RC-bin→GGL-bin; oddzielne „dostrajanie odwzorowania” dla pojedynczego zbioru danych jest niedozwolone;
(iii) Test domknięcia: każde wzmocnienie musi wykazać rzeczywisty zysk w predykcji transferowej RC→GGL, a nie tylko lepsze dopasowanie RC-only.
B.2 DM 7+1 + DM_STD: definicje modułów, parametry i wejście do wspólnego posteriora
Jako niezależny runpack P1A udostępnia 8 przestrzeni roboczych DM (DM 7+1) plus 1 kontrolę EFT: wychodząc od DM_RAZOR jako linii bazowej, konstruuje trzy starsze jednoparametrowe wzmocnienia (DM_RAZOR_SCAT / DM_RAZOR_AC / DM_RAZOR_FB), dodaje trzy bardziej standardowe moduły defensywne (DM_HIER_CMSCAT / DM_CORE1P / DM_RAZOR_M), a następnie udostępnia model łączony DM_STD. Wspólnym celem tych modułów jest objęcie trzech najczęstszych klas krytyki przy możliwie najmniejszym zwiększeniu wymiarowości: (a) jak rozrzut c–M i priory wchodzą do modelu hierarchicznego; (b) czy główny efekt feedbacku barionowego można uchwycić jednoparametrowym proxy jądra; oraz (c) czy kluczowe systematyki po stronie soczewkowania mogą zostać pomylone z sygnałem fizycznym.
Przestrzeń robocza | dm_model | Nowe parametry (≤1) | Motywacja fizyczna (rdzeń) | Zasada implementacji (przyjazna audytowi) |
|---|---|---|---|---|
DM_RAZOR | NFW (stałe c–M, bez rozrzutu) | — | Minimalna, audytowalna linia bazowa halo ΛCDM; używana do ścisłego porównania z EFT | Wspólne odwzorowanie stałe; ścisła księga parametrów; używana jako linia bazowa wyłącznie do porównań względnych |
DM_RAZOR_SCAT | NFW + rozrzut c–M (legacy) | σ_logc | Relacja c–M ma rozrzut; przybliżona jednoparametrowym rozrzutem lognormalnym | ≤1 nowy parametr; zachowane wspólne odwzorowanie; zysk domknięcia używany jako kryterium akceptacji |
DM_RAZOR_AC | NFW + kontrakcja adiabatyczna (legacy) | α_AC | Napływ barionów może wywołać kontrakcję adiabatyczną halo; przybliżoną jednoparametrową siłą | ≤1 nowy parametr; odwzorowanie bez zmian; raportowane zmiany AICc/BIC i zysk domknięcia |
DM_RAZOR_FB | NFW + jądro feedbacku (legacy) | log r_core | Feedback może utworzyć jądro w obszarze wewnętrznym; przybliżony jednoparametrową skalą jądra | ≤1 nowy parametr; ten sam protokół domknięcia/kontroli negatywnej; poprawa RC-only nie jest jedynym celem |
DM_HIER_CMSCAT | Hierarchiczny rozrzut c–M + prior | σ_logc (hier) | Bardziej standardowe hierarchiczne c_i∼logN(c(M_i),σ_logc); wpływa na wspólny posterior RC i GGL | Jawny prior; ukryte c_i marginalizowane; nadal niskowymiarowe i audytowalne |
DM_CORE1P | Jednoparametrowy proxy jądra (inspirowany coreNFW/DC14) | log r_core | Używa jednoparametrowego proxy jądra dla głównego efektu feedbacku barionowego, unikając wysokowymiarowych szczegółów formowania gwiazd | Odwołuje się do standardowej literatury; ≤1 nowy parametr; powiązane z testem domknięcia |
DM_RAZOR_M | NFW + nuisance kalibracji ścinania soczewkowania | m_shear (GGL) | Absorbuje kluczową systematykę słabego soczewkowania jako parametr efektywny, zmniejszając ryzyko pomylenia systematyk z fizyką | Nuisance jawnie zapisane; nie może działać wstecz na RC; wyniki oceniane głównie przez odporność domknięcia |
DM_STD | Standaryzowana linia bazowa DM (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | Obejmuje trzy najczęstsze klasy krytyki w nadal niskowymiarowej standardowej linii bazowej | Raportowane księga parametrów + kryteria informacyjne; domknięcie jest metryką główną; używana jako najsilniejsza kontrola defensywna DM |
Uwaga: powyższe nazwy parametrów są zgodne z implementacją inżynieryjną (np. σ_logc, α_AC, log r_core i m_shear). Celem projektowym P1A jest „nieco wzmocnić linię bazową DM, zachowując jej audytowalność”, a nie przekształcić stronę DM w niekontrolowalny wysokowymiarowy fitter. W szczególności DM_HIER_CMSCAT wprowadza rozrzut c–M hierarchicznie: koncentracja c_i każdego halo otrzymuje lognormalny rozrzut wokół c(M_i), ograniczony przez globalne σ_logc i prior c(M); ta struktura hierarchiczna wpływa na wspólny posterior zarówno RC, jak i GGL.
B.3 Protokół statystyczny i konwencje produktów zgodne z tekstem głównym
P1A ponownie wykorzystuje wszystkie produkty danych, wspólne odwzorowanie i ramy audytu z tekstu głównego. Kolejność wykonania i konwencje produktów pozostają spójne:
(1) Run‑1: inferencja RC-only (produkty posterior_samples.npz i metrics.json);
(2) Run‑2: test domknięcia RC→GGL (produkty closure_summary.json i permutowana linia bazowa);
(3) Run‑3: wspólne dopasowanie RC+GGL (produkt joint_summary.json).
Wszystkie cytowane liczby pochodzą z automatycznie skompilowanej tabeli (Tab_S1_P1A_scoreboard) i można je sprawdzić po ponownym uruchomieniu pełnego przepływu P1A za pomocą skryptu porównania tabel referencyjnych wbudowanego w P1A full_fit_runpack.
B.4 Główne wyniki, punkty wejścia do tabel/rysunków i plan archiwizacji (to samo DOI)
Ta sekcja podaje rdzeniowe wnioski ilościowe P1A. Tabela B1 podsumowuje kluczowe metryki dla RC-only, domknięcia RC→GGL i wspólnego dopasowania RC+GGL (w nawiasach różnice względem linii bazowej DM_RAZOR). Siłę domknięcia definiuje się jako ΔlogL_closure ≡ ⟨logL_true⟩ − ⟨logL_perm⟩ (więcej znaczy lepiej). Rys. B1 wizualizuje tę samą tablicę wyników. Główne punkty są następujące:
• Spośród trzech starszych gałęzi tylko DM_RAZOR_FB (feedback/core) daje niewielką poprawę netto siły domknięcia: 122.21→129.45 (+7.25); SCAT i AC nie dają poprawy netto;
• Nowo dodane DM_HIER_CMSCAT i DM_RAZOR_M mają bardzo mały wpływ (~0) na siłę domknięcia, a DM_CORE1P również nie wykazuje istotnej poprawy netto;
• Model łączony DM_STD może znacznie poprawić wspólne logL (zbliżyć się do optimum dopasowania wspólnego), ale jego siła domknięcia maleje, co sugeruje, że zysk pochodzi głównie z elastyczności dopasowania wspólnego, a nie z przenoszalności między sondami;
• Jako kontrola EFT_BIN nadal zachowuje wyraźną przewagę zarówno w sile domknięcia, jak i w dopasowaniu wspólnym. Główny wniosek pozostaje więc odporny na wprowadzenie „silniejszej linii bazowej DM + nuisance soczewkowania”.
Dla bezpośredniego porównania z wynikami tekstu głównego tabele S1a–S1b podsumowują ścisłe porównanie rodziny EFT i DM_RAZOR: modele EFT poprawiają dopasowanie wspólne o ΔlogL_total≈1155–1337 względem DM_RAZOR i osiągają ΔlogL_closure=172–281 w teście domknięcia. P1A tworzy jedynie „trudniejszą kontrolę” po stronie DM; jego celem jest zmniejszenie obaw typu „słomiana linia bazowa” lub „systematyki jako fizyka”, a nie zastąpienie głównego porównania.
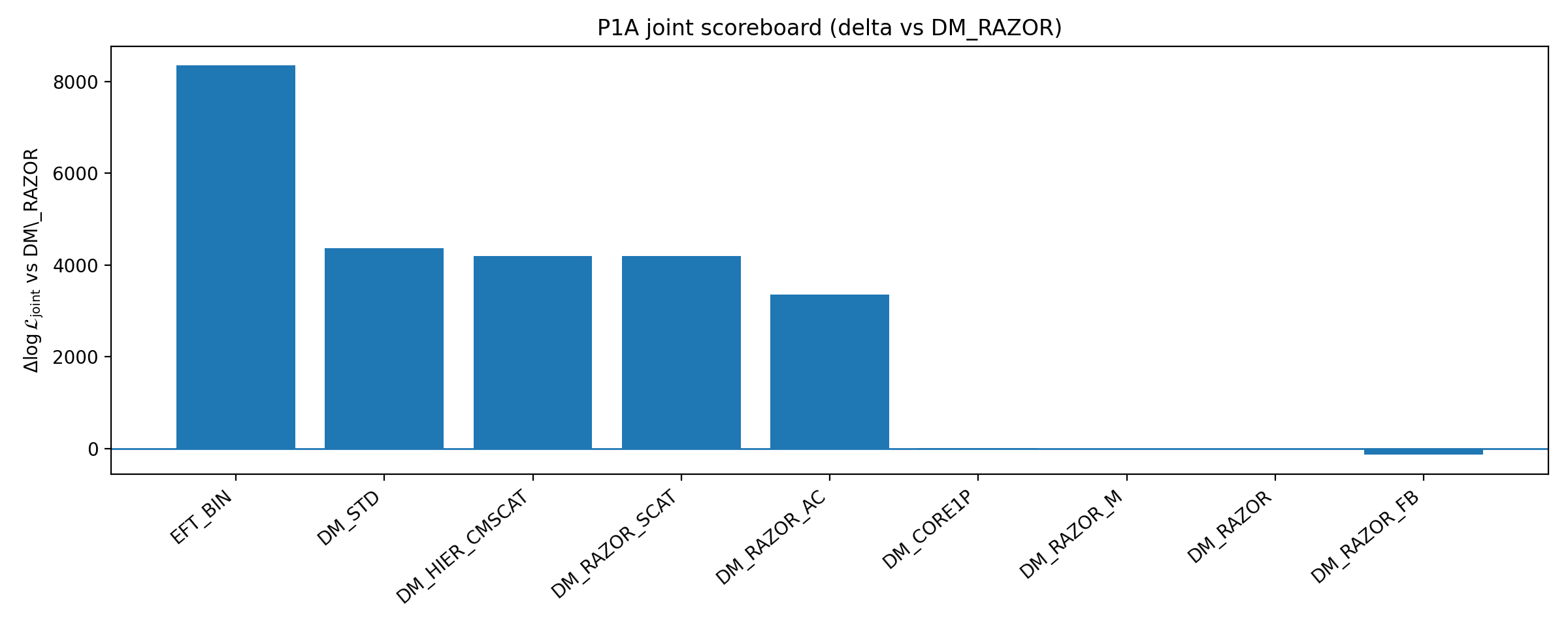
Tabela B1 | Tablica wyników P1A (więcej znaczy lepiej; nawiasy oznaczają różnice względem linii bazowej DM_RAZOR).
Gałąź modelu (przestrzeń robocza) | Δk | Najlepsze logL_RC dla RC-only (Δ) | Siła domknięcia ΔlogL_closure (Δ) | Najlepsze wspólne logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
Rys. B1 | Tablica wyników P1A: domknięcie i wspólne ΔlogL względem linii bazowej (więcej znaczy lepiej).
Przykładowe tagi dla ukończonego zestawu uruchomień odpowiadającego temu dodatkowi są następujące (służą do lokalizacji produktów pośrednich P1A oraz tabel/rysunków):
P1A run_tag = 20260213_151233; P1A closure_tag = 20260213_161731; P1A joint_tag = 20260213_195428.
B.5 Sugerowane cytowanie (uwaga cytacyjna do dodatku)
Gdy czytelnicy potrzebują zacytować „test standaryzacji linii bazowej DM” oprócz głównych wniosków artykułu, zaleca się cytowanie głównego wniosku wraz z następującą uwagą: „See Appendix B (P1A) for standardized DM-baseline stress tests (legacy SCAT/AC/FB + hierarchical c–M scatter prior + core proxy + lensing shear-calibration nuisance), under the same closure protocol.”